
Textual content retrieval is important for purposes like looking, query answering, semantic similarity, and merchandise suggestion. Embedding or dense retrieval fashions play a key position on this course of. The hard-negative mining methodology is used, to pick out adverse passages for queries to coach these fashions. It includes a instructor retrieval mannequin to seek out passages associated to the question, however not related in comparison with the optimistic passages, making it troublesome for the mannequin to distinguish positives from negatives. The hard-negatives methodology is more difficult to tell apart from the positives than the negatives. Regardless of its significance, hard-negative mining strategies typically present unhealthy efficiency underexplored in textual content retrieval analysis, which usually focuses on mannequin architectures, fine-tuning strategies, and coaching information.
Present strategies like textual content embedding fashions flip variable-length textual content into fixed-size vectors. Below this, Sentence-BERT was a key improvement, modifying the BERT community to symbolize pairs of associated brief texts in the identical area utilizing siamese or triplet networks. Additional, Contrastive studying (CL) turned well-liked with SimCLR, which demonstrated it was more practical than classification-based losses for embeddings. One other methodology is hard-negative mining for fine-tuning embeddings. It selects adverse passages from optimistic ones in the identical batch, effectively utilizing embeddings from the coaching move. Nonetheless, the variety of negatives is proscribed by the batch dimension, the place some options make the most of a cache or reminiscence financial institution with embeddings from previous batches or combining batches from totally different GPUs.
A crew of researchers from NVIDIA have launched a state-of-the-art embedding mannequin known as NV-Retriever-v1. It’s a household of hard-negative mining strategies that makes use of the optimistic relevance rating, to take away false negatives extra successfully. It carried out exceptionally nicely, scoring a mean of 60.9 throughout 15 BEIR datasets, and took first place on the MTEB Retrieval leaderboard when it was printed there on July eleventh, 2024. A key methodology for coaching this mannequin is hard-negative mining, which is essential for attaining high efficiency in textual content retrieval. This contains choosing the top-k most related candidates to the question, after ignoring the optimistic passages, which known as Naive High-Okay.
The MTEB contains duties like retrieval, reranking, classification, and clustering, so there’s a requirement for varied coaching datasets for it to carry out nicely. The tactic NV-Retriever-v1 is fine-tuned utilizing the E5-Mistral-7B embedding mannequin for hard-negative mining with a most sequence size of 4096. The proposed methodology, TopK-PercPos is used to keep away from false negatives, setting the adverse relevance rating threshold at 95% of the optimistic rating. Furthermore, there are two phases of instruction tuning. Within the first stage, retrieval supervised information with in-batch negatives and mined hard-negative are used. Within the second stage, the information for the retrieval job is mixed with datasets from different duties.
Researchers in contrast adverse mining strategies in managed experiments utilizing the identical hyperparameters on a subset of the BEIR datasets. NV-Retriever-v1 assessments the most effective setup for positive-aware mining strategies on the complete MTEB BEIR benchmark and compares it to different top-performing fashions. NV-Retriever-v1 achieves a mean NDCG@10 rating of 60.9, putting it 1st as of July eleventh, 2024. The skilled NV-Retriever-v1 makes use of positive-aware mining strategies and outperforms the most effective fashions by 0.65 factors. It’s a important enhancement for the highest positions on the leaderboard.
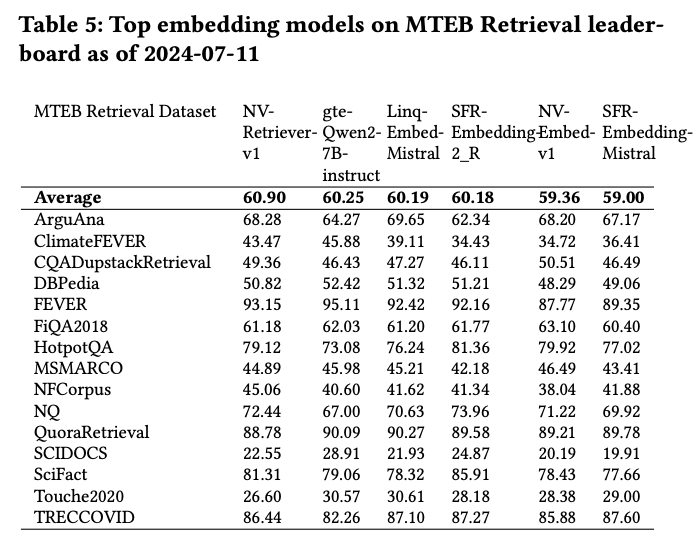
On this paper, researchers from NVIDIA have proposed NV-Retriever-v1, a state-of-the-art textual content embedding mannequin. They current an in depth research evaluating totally different strategies for hard-negative mining, varied instructor fashions, and the mixture of their onerous negatives, exhibiting how these selections impression the accuracy of the fine-tuned textual content embedding fashions. On the publishing time, NV-Retriever-v1 ranked first on the MTEB Retrieval/BEIR benchmark. This research on hard-negative mining encourages additional analysis and helps extra correct fine-tuning of textual content embedding fashions. Researchers strongly encourage future work on this space to reveal their methodology for mining, which incorporates specifying the instructor mannequin and mining methodology used to make sure that outcomes may be reproduced and replicated.
Try the Paper and Mannequin Card. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here

Sajjad Ansari is a last 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a give attention to understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.



