A big problem within the subject of visible query answering (VQA) is the duty of Multi-Picture Visible Query Answering (MIQA). This entails producing related and grounded responses to pure language queries based mostly on a big set of photos. Present Giant Multimodal Fashions (LMMs) excel in single-image visible query answering however face substantial difficulties when queries span in depth picture collections. Addressing this problem is essential for real-world functions like looking by giant picture albums, discovering particular info throughout the web, or monitoring environmental modifications by satellite tv for pc imagery.
Present strategies for visible query answering primarily give attention to single-image evaluation, which limits their utility for extra advanced queries involving giant picture units. Fashions like Gemini 1.5-pro and GPT-4V can course of a number of photos however encounter important challenges in effectively retrieving and integrating related photos from giant datasets. These strategies are computationally inefficient and exhibit efficiency degradation as the amount and variability of photos improve. Additionally they undergo from positional bias and wrestle with integrating visible info throughout quite a few unrelated photos, resulting in a decline in accuracy and applicability in large-scale duties.
To deal with these limitations, researchers from the College of California suggest MIRAGE (Multi-Picture Retrieval Augmented Era), a novel framework tailor-made for MIQA. MIRAGE extends the LLaVA mannequin by integrating a number of revolutionary elements: a compressive picture encoder, a retrieval-based, query-aware relevance filter, and augmented coaching with focused artificial and actual MIQA information. These improvements allow MIRAGE to deal with bigger picture contexts effectively and enhance accuracy in answering MIQA duties. This method represents a big contribution to the sphere, providing as much as an 11% accuracy enchancment over closed-source fashions like GPT-4o on the Visible Haystacks (VHs) benchmark, and demonstrating as much as 3.4x enhancements in effectivity over conventional text-focused multi-stage approaches.
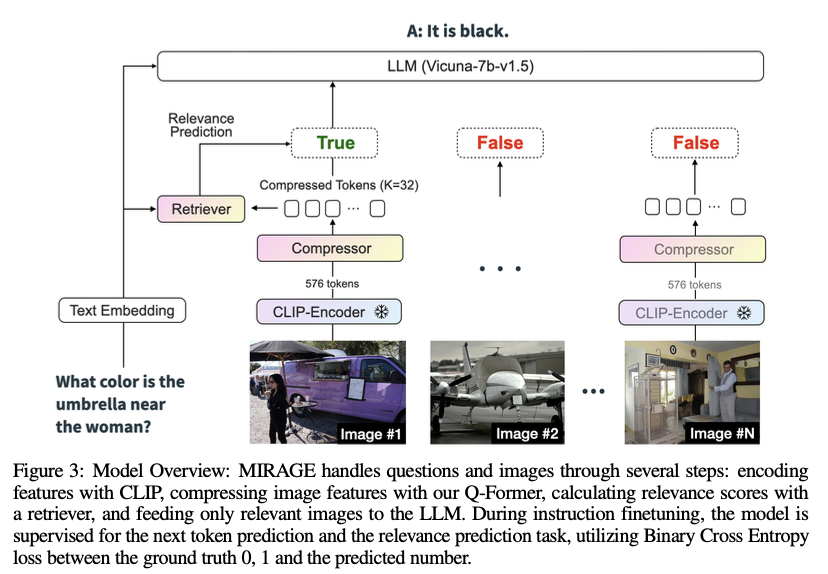
MIRAGE employs a compressive picture encoding mechanism utilizing a Q-former to cut back the token depth per picture from 576 to 32 tokens. This permits the mannequin to deal with extra photos inside the similar context funds. The query-aware relevance filter is a single-layer MLP that predicts the relevance of photos to the question, which is then used to pick out related photos for detailed evaluation. The coaching course of entails each present MIQA datasets and artificial information derived from single-image QA datasets, enhancing the mannequin’s robustness and efficiency throughout diversified MIQA eventualities. The VHs dataset used for benchmarking comprises 880 single-needle and 1000 multi-needle question-answer pairs, offering a rigorous analysis framework for MIQA fashions.
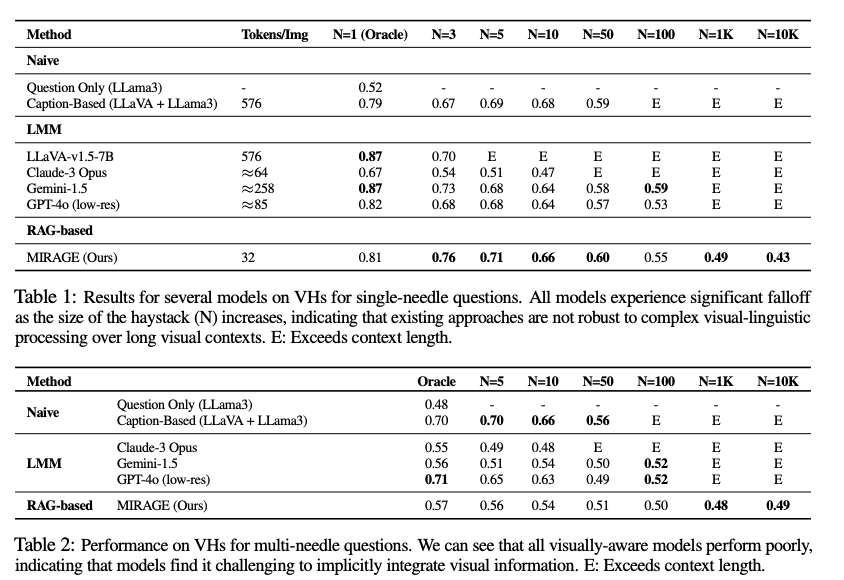
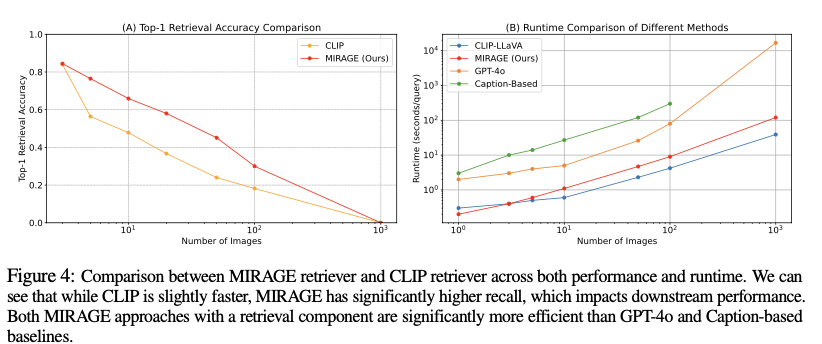
Analysis outcomes present that MIRAGE considerably outperforms present fashions on the Visible Haystacks benchmark, surpassing closed-source fashions like GPT-4o by as much as 11% in accuracy for single-needle questions and demonstrating notable enhancements in effectivity. MIRAGE maintains increased efficiency ranges as the dimensions of the picture units will increase, showcasing its robustness in dealing with in depth visible contexts. It achieved substantial enhancements in each accuracy and processing effectivity in comparison with conventional text-focused multi-stage approaches.
In conclusion, the researchers current a big development in MIQA with the MIRAGE framework. The important problem of effectively retrieving and integrating related photos from giant datasets to reply advanced visible queries is addressed. MIRAGE’s revolutionary elements and strong coaching strategies result in superior efficiency and effectivity in comparison with present fashions, paving the best way for simpler AI functions in real-world eventualities involving in depth visible information.
Try the Paper, Undertaking, GitHub, and Particulars. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s keen about information science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.