
Multi-modal generative fashions combine varied information sorts, similar to textual content, photos, and movies, increasing AI purposes throughout completely different fields. Nonetheless, optimizing these fashions presents advanced challenges associated to information processing and mannequin coaching. The necessity for cohesive methods to refine each information and fashions is essential for reaching superior AI efficiency.
A serious difficulty in multi-modal generative mannequin growth is the remoted development of data-centric and model-centric approaches. Researchers typically wrestle to combine information processing and mannequin coaching, resulting in inefficiencies and suboptimal outcomes. This separation hampers the power to boost information and fashions concurrently, which is important for bettering AI capabilities.
Present strategies for creating multi-modal generative fashions usually focus both on refining algorithms and mannequin architectures or enhancing information processing strategies. These strategies function independently, counting on heuristic approaches and human instinct. Consequently, they lack systematic steering for collaborative optimization of knowledge and fashions, leading to fragmented and fewer efficient growth efforts.
Researchers from Alibaba Group have launched the Knowledge-Juicer Sandbox, an open-source suite, to deal with these challenges. This sandbox facilitates the co-development of multi-modal information and generative fashions by integrating a wide range of customizable parts. It presents a versatile platform for systematic exploration and optimization, bridging the hole between information processing and mannequin coaching. The suite is designed to streamline the event course of and improve the synergy between information and fashions.
The Knowledge-Juicer Sandbox employs a “Probe-Analyze-Refine” workflow, permitting researchers to check and refine completely different information processing operators (OPs) and mannequin configurations systematically. This methodology includes creating equal-size information swimming pools, every processed uniquely by a single OP. Fashions are skilled on these information swimming pools, enabling in-depth evaluation of OP effectiveness and its correlation with mannequin efficiency throughout varied quantitative and qualitative indicators. This systematic strategy improves each information high quality and mannequin efficiency, offering useful insights into the advanced interaction between information preprocessing and mannequin habits.
Of their methodology, the researchers applied a hierarchical information pyramid, categorizing information swimming pools based mostly on their ranked mannequin metric scores. This stratification helps determine the simplest OPs, that are then mixed into information recipes and scaled up. By sustaining constant hyperparameters and utilizing cost-effective methods like downsizing information swimming pools and limiting coaching iterations, the researchers ensured an environment friendly and resource-conscious growth course of. The sandbox’s compatibility with current model-centric infrastructures makes it a flexible software for AI growth.
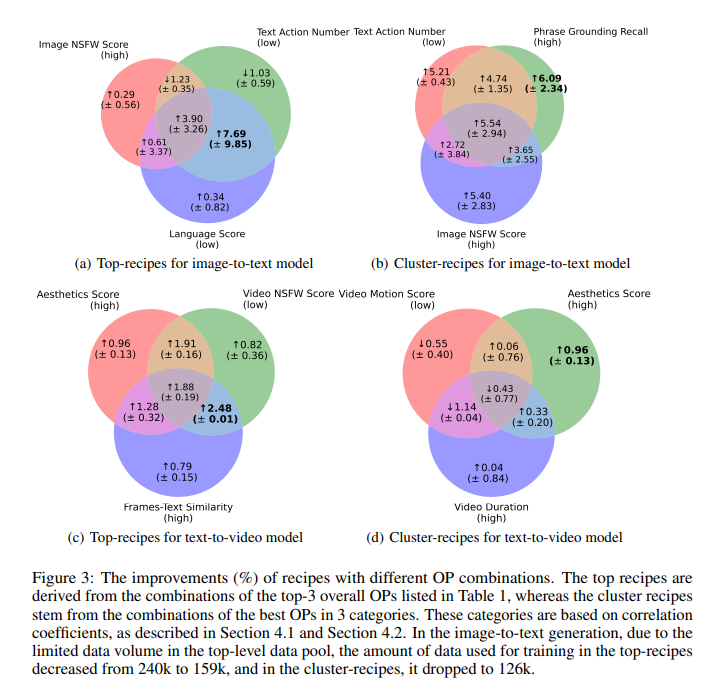
The Knowledge-Juicer Sandbox achieved important efficiency enhancements in a number of duties. For image-to-text era, the common efficiency on TextVQA, MMBench, and MME elevated by 7.13%. In text-to-video era, utilizing the EasyAnimate mannequin, the sandbox achieved the highest spot on the VBench leaderboard, outperforming sturdy opponents. The experiments additionally demonstrated a 59.9% enhance in aesthetic scores and a 49.9% enchancment in language scores when utilizing high-quality information swimming pools. These outcomes spotlight the sandbox’s effectiveness in optimizing multi-modal generative fashions.
Furthermore, the sandbox facilitated sensible purposes in two distinct situations: image-to-text era and text-to-video era. Within the image-to-text process, utilizing the Mini-Gemini mannequin, the sandbox achieved top-tier efficiency in understanding picture content material. For the text-to-video process, the EasyAnimate mannequin demonstrated the sandbox’s functionality to generate high-quality movies from textual descriptions. These purposes exemplified the sandbox’s versatility and effectiveness in enhancing multi-modal data-model co-development.
In conclusion, the Knowledge-Juicer Sandbox addresses the important downside of integrating information processing and mannequin coaching in multi-modal generative fashions. By offering a scientific and versatile platform for co-development, it permits researchers to attain important enhancements in AI efficiency. This modern strategy represents a serious development within the discipline of AI, providing a complete answer to the challenges of optimizing multi-modal generative fashions.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication..
Don’t Neglect to hitch our 46k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.



