
Language fashions (LMs) face important challenges associated to privateness and copyright issues attributable to their coaching on huge quantities of textual content knowledge. The inadvertent inclusion of personal and copyrighted content material in coaching datasets has led to authorized and moral points, together with copyright lawsuits and compliance necessities with rules like GDPR. Knowledge homeowners more and more demand the removing of their knowledge from educated fashions, highlighting the necessity for efficient machine unlearning strategies. These developments have spurred analysis into strategies that may remodel present educated fashions to behave as if that they had by no means been uncovered to sure knowledge, whereas sustaining total efficiency and effectivity.
Researchers have made numerous makes an attempt to handle the challenges of machine unlearning in language fashions. Precise unlearning strategies, which purpose to make the unlearned mannequin equivalent to a mannequin retrained with out the forgotten knowledge, have been developed for easy fashions like SVMs and naive Bayes classifiers. Nonetheless, these approaches are computationally infeasible for contemporary giant language fashions.
Approximate unlearning strategies have emerged as extra sensible alternate options. These embody parameter optimization strategies like Gradient Ascent, localization-informed unlearning that targets particular mannequin models, and in-context unlearning that modifies mannequin outputs utilizing exterior data. Researchers have additionally explored making use of unlearning to particular downstream duties and for eliminating dangerous behaviors in language fashions.
Analysis strategies for machine unlearning in language fashions have primarily centered on particular duties like query answering or sentence completion. Metrics corresponding to familiarity scores and comparisons with retrained fashions have been used to evaluate unlearning effectiveness. Nonetheless, present evaluations typically lack comprehensiveness and fail to adequately tackle real-world deployment issues like scalability and sequential unlearning requests.
Researchers from the College of Washington, Princeton College, the College of Southern California, the College of Chicago, and Google Analysis introduce MUSE (Machine Unlearning Six-Means Analysis), a complete framework designed to evaluate the effectiveness of machine unlearning algorithms for language fashions. This systematic method evaluates six important properties that tackle each knowledge homeowners’ and mannequin deployers’ necessities for sensible unlearning. MUSE examines the power of unlearning algorithms to take away verbatim memorization, data memorization, and privateness leakage whereas additionally assessing their capability to protect utility, scale successfully, and maintain efficiency throughout a number of unlearning requests. By making use of this framework to judge eight consultant machine unlearning algorithms on datasets centered on unlearning Harry Potter books and information articles, MUSE offers a holistic view of the present state and limitations of unlearning strategies in real-world eventualities.
MUSE proposes a complete set of analysis metrics that tackle each knowledge proprietor and mannequin deployer expectations for machine unlearning in language fashions. The framework consists of six key standards:
Knowledge Proprietor Expectations:
1. No verbatim memorization: Measured by prompting the mannequin with the start of a sequence from the overlook set and evaluating the mannequin’s continuation with the true continuation utilizing ROUGE-L F1 rating.
2. No data memorization: Assessed by testing the mannequin’s capacity to reply questions derived from the overlook set, utilizing ROUGE scores to check model-generated solutions with true solutions.
3. No privateness leakage: Evaluated utilizing a membership inference assault (MIA) technique to detect if the mannequin retains data indicating that the overlook set was a part of the coaching knowledge.
Mannequin Deployer Expectations:
4. Utility preservation: Measured by evaluating the mannequin’s efficiency on the retain set utilizing the data memorization metric.
5. Scalability: Assessed by inspecting the mannequin’s efficiency on overlook units of various sizes.
6. Sustainability: Analyzed by monitoring the mannequin’s efficiency over sequential unlearning requests.
MUSE evaluates these metrics on two consultant datasets: NEWS (BBC information articles) and BOOKS (Harry Potter sequence), offering a sensible testbed for assessing unlearning algorithms in sensible eventualities.
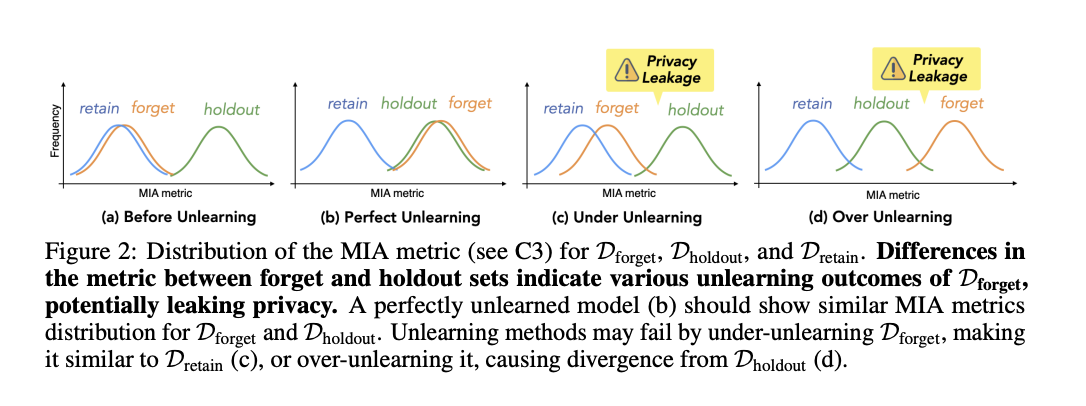
The MUSE framework’s analysis of eight unlearning strategies revealed important challenges in machine unlearning for language fashions. Whereas most strategies successfully eliminated verbatim and data memorization, they struggled with privateness leakage, typically under- or over-unlearning. All strategies considerably degraded mannequin utility, with some rendering fashions unusable. Scalability points emerged as overlook set sizes elevated, and sustainability proved problematic with sequential unlearning requests, resulting in progressive efficiency degradation. These findings underscore the substantial trade-offs and limitations in present unlearning strategies, highlighting the urgent want for more practical and balanced approaches to satisfy each knowledge proprietor and deployer expectations.
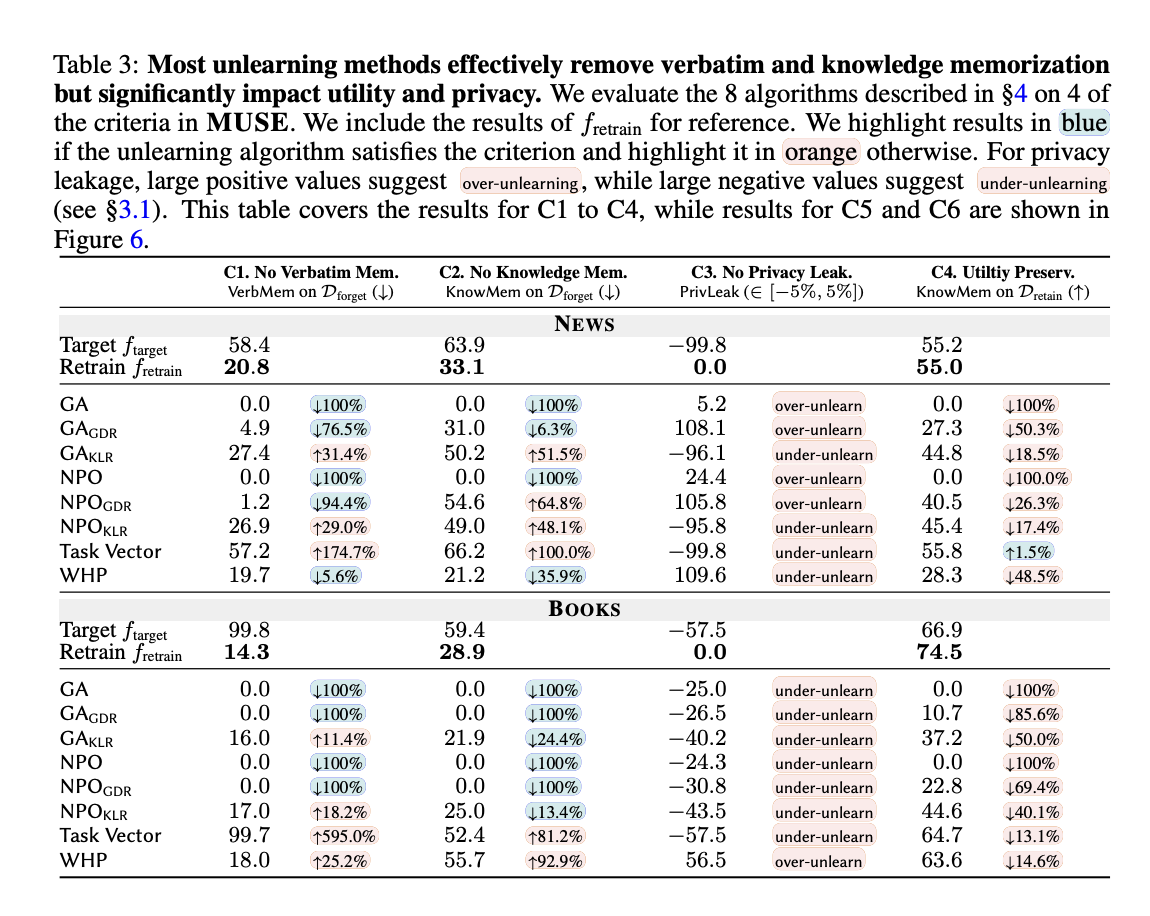
This analysis introduces MUSE, a complete machine unlearning analysis benchmark, assesses six key properties essential for each knowledge homeowners and mannequin deployers. The analysis reveals that whereas present unlearning strategies successfully forestall content material memorization, they achieve this at a considerable value to mannequin utility on retained knowledge. Additionally, these strategies typically lead to important privateness leakage and battle with scalability and sustainability when dealing with large-scale content material removing or successive unlearning requests. These findings underscore the restrictions of present approaches and emphasize the pressing want for creating extra sturdy and balanced machine unlearning strategies that may higher tackle the complicated necessities of real-world purposes.
Try the Paper and Undertaking. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 46k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


