
Evaluating massive language fashions (LLMs) has turn into more and more difficult resulting from their complexity and flexibility. Guaranteeing the reliability and high quality of those fashions’ outputs is essential for advancing AI applied sciences and functions. Researchers need assistance growing dependable analysis strategies to evaluate the accuracy and impartiality of LLMs’ outputs, given human evaluations’ subjective, inconsistent, and expensive nature.
Present analysis metrics like BLEU and ROUGE primarily give attention to lexical overlaps and fail to seize the nuanced high quality of LLM outputs. Though current strategies have utilized pretrained fashions to measure distributional similarity and token possibilities, these approaches nonetheless have to be revised in generalizability and consistency. The excessive value and time required for human evaluations additional complicate the method, making it impractical for large-scale assessments.
A analysis staff from Google DeepMind, Google, and UMass Amherst have launched FLAMe, a household of Foundational Giant Autorater Fashions designed to enhance the analysis of LLMs. FLAMe leverages a big and various assortment of high quality evaluation duties derived from human judgments to coach and standardize autoraters. FLAMe is skilled utilizing supervised multitask fine-tuning on over 100 high quality evaluation duties, encompassing greater than 5 million human judgments. This coaching employs a text-to-text format, facilitating efficient switch studying throughout capabilities. The strategy permits FLAMe to generalize to new duties, outperforming current fashions like GPT-4 and Claude-3.
The coaching of FLAMe entails a meticulous course of of knowledge assortment and standardization. The analysis staff curated human evaluations from earlier research, specializing in duties comparable to machine translation high quality and AI assistant instruction. This in depth dataset was then reformatted right into a unified text-to-text format, the place every high quality evaluation activity was transformed into input-target pairs. The inputs embody task-specific contexts, whereas the targets include anticipated human evaluations. By coaching on this huge and various dataset, FLAMe learns sturdy patterns of human judgment, minimizing the influence of noisy or low-quality information. The FLAMe-RM variant, particularly fine-tuned for reward modeling analysis, exemplifies this technique’s effectiveness. Superb-tuned for less than 50 steps on a mix of 4 datasets protecting chat, reasoning, and security, FLAMe-RM demonstrates important enhancements in efficiency.
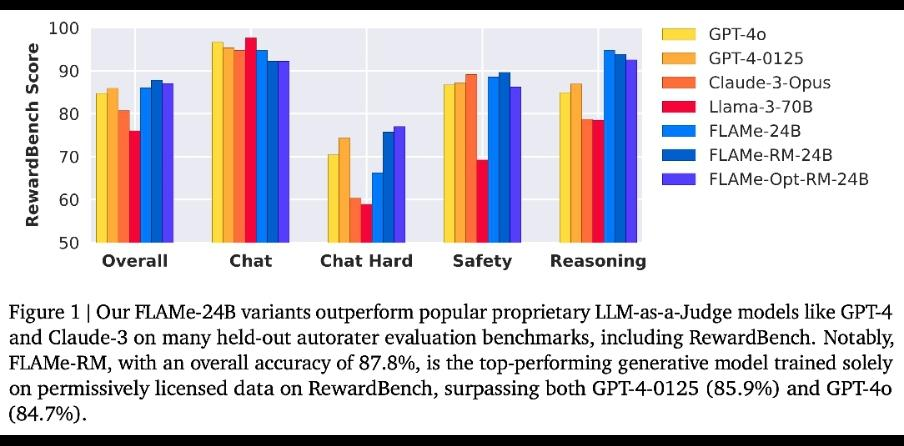
The efficiency of FLAMe is noteworthy throughout numerous benchmarks. The FLAMe-RM-24B mannequin, a variant fine-tuned for reward modeling analysis, achieved an accuracy of 87.8% on RewardBench, surpassing each GPT-4-0125 (85.9%) and GPT-4o (84.7%). On the CoBBLEr bias benchmark, FLAMe displays considerably decrease bias in comparison with different autorater fashions. Along with RewardBench, FLAMe’s efficiency is powerful on different benchmarks. The FLAMe fashions outperform current LLMs on 8 out of 12 automated analysis benchmarks, protecting 53 high quality evaluation duties. This consists of duties comparable to abstract comparisons, helpfulness evaluations, and factual accuracy assessments. The outcomes display FLAMe’s broad applicability and sturdy efficiency throughout various analysis situations.
FLAMe-Decide-RM, a computationally environment friendly variant, optimizes the multitask combination for reward modeling analysis utilizing a novel tail-patch fine-tuning technique. This methodology fine-tunes the preliminary instruction-tuned PaLM-2-24B checkpoint on an optimized combination for 5000 steps, attaining aggressive RewardBench efficiency with roughly 25 instances fewer coaching information factors. The analysis highlights that longer coaching and extra fine-tuning can enhance efficiency, suggesting that FLAMe-Decide-RM is a flexible and environment friendly mannequin.
To conclude, the analysis highlights the significance of dependable and environment friendly analysis strategies for LLMs. FLAMe affords a strong resolution by leveraging standardized human evaluations, demonstrating important enhancements in efficiency and bias discount. This development is poised to reinforce the event and deployment of AI applied sciences. The FLAMe household of fashions, developed by a collaborative staff from Google DeepMind, Google, and UMass Amherst, represents a big step ahead in evaluating massive language fashions, guaranteeing their outputs are dependable, unbiased, and of top quality.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our 46k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


