
Evaluating the effectiveness of Massive Language Mannequin (LLM) compression methods is a vital problem in AI. Compression strategies like quantization goal to optimize LLM effectivity by lowering computational prices and latency. Nonetheless, conventional analysis practices focus totally on accuracy metrics, which fail to seize modifications in mannequin conduct, such because the phenomenon of “flips” the place right solutions flip incorrect and vice versa. This problem is critical because it impacts the reliability and consistency of compressed fashions in numerous vital functions, together with medical analysis and autonomous driving.
Present strategies for evaluating LLM compression methods rely closely on accuracy metrics from benchmark duties like MMLU, Hellaswag, and ARC. These strategies contain measuring the efficiency of compressed fashions towards baseline fashions by evaluating their accuracy on predefined duties. Nonetheless, this strategy overlooks the incidence of flips, the place compressed fashions might produce totally different solutions regardless of having comparable accuracy ranges. This may result in a deceptive notion of the mannequin’s reliability. Furthermore, accuracy metrics alone don’t account for qualitative variations in mannequin conduct, particularly in duties involving generative responses, the place the nuances of language technology are vital.
The researchers from Microsoft Analysis, India, suggest a novel strategy to evaluating LLM compression methods by introducing distance metrics reminiscent of KL-Divergence and % flips, along with conventional accuracy metrics. This strategy offers a extra complete analysis of how carefully compressed fashions mimic their baseline counterparts. The core innovation lies within the identification and quantification of flips, which function an intuitive and simply interpretable metric of mannequin divergence. By specializing in each qualitative and quantitative points of mannequin efficiency, this strategy ensures that compressed fashions preserve excessive requirements of reliability and applicability throughout numerous duties.
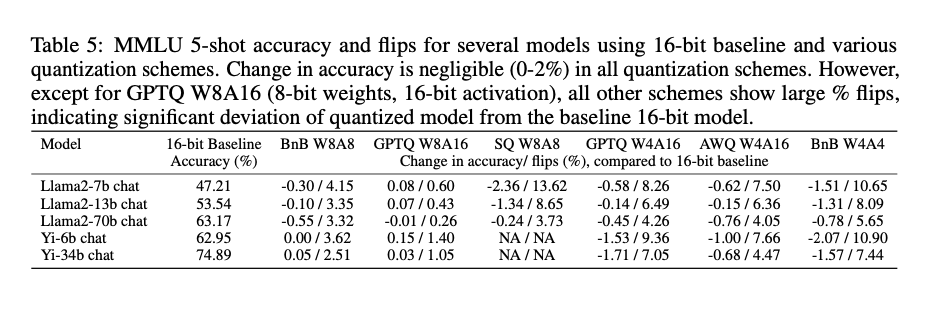
The research particulars experiments performed utilizing a number of LLMs (e.g., Llama2 and Yi chat fashions) and numerous quantization methods (e.g., LLM.int8, GPTQ, AWQ). The researchers consider these methods on a number of duties, together with MMLU, ARC, PIQA, Winogrande, Hellaswag, and Lambada. The analysis metrics embrace accuracy, perplexity, flips, and KL-Divergence. Notably, the flips metric measures the proportion of solutions that change from right to incorrect and vice versa between the baseline and compressed fashions. The dataset traits and hyperparameter tuning methods for every mannequin are fastidiously outlined, making certain a strong experimental setup.
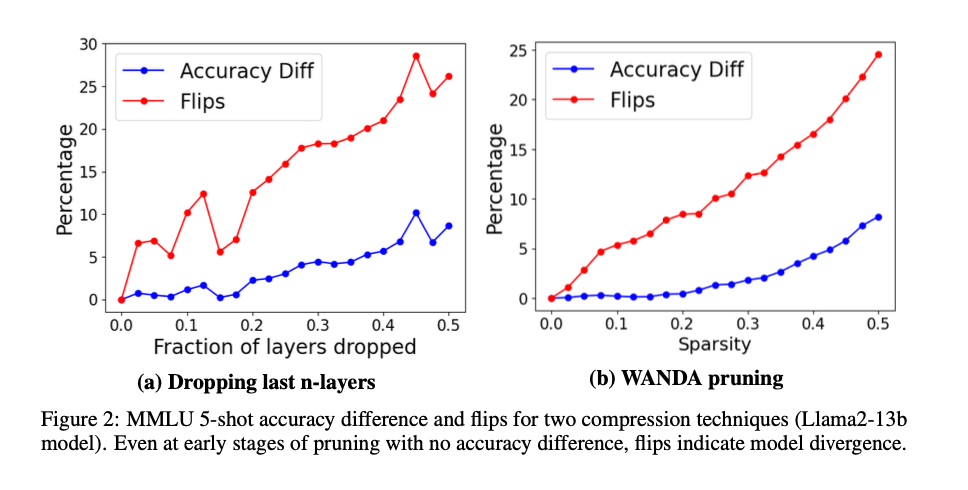
The findings reveal that whereas accuracy variations between baseline and compressed fashions are sometimes negligible (≤2%), the proportion of flips will be substantial (≥5%), indicating vital divergence in mannequin conduct. As an example, within the MMLU process, the GPTQ W8A16 quantization scheme achieves an accuracy of 63.17% with solely a 0.26% flip price, demonstrating excessive constancy to the baseline mannequin. In distinction, different quantization schemes present vital deviations, with flip charges as excessive as 13.6%. The research additionally exhibits that bigger fashions usually have fewer flips than smaller ones, indicating better resilience to compression. Moreover, qualitative analysis utilizing MT-Bench reveals that fashions with larger flip charges carry out worse in generative duties, additional validating the proposed metrics’ effectiveness in capturing nuanced efficiency modifications.
In conclusion, this proposed methodology makes a major contribution to AI analysis by proposing a extra complete analysis framework for LLM compression methods. It identifies the constraints of relying solely on accuracy metrics and introduces the flips and KL-Divergence metrics to higher seize mannequin divergence. This strategy ensures that compressed fashions preserve excessive reliability and applicability, advancing the sector of AI by addressing a vital problem in mannequin analysis.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Overlook to hitch our 46k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.


