
Within the realm of Massive language fashions (LLMs), there was a big transformation in textual content era, prompting researchers to discover their potential in audio synthesis. The problem lies in adapting these fashions for text-to-speech (TTS) duties whereas sustaining high-quality output. Present methodologies, akin to neural codec language fashions like VALL-E, face a number of limitations. These embody decrease constancy in comparison with mel-spectrograms, robustness points stemming from random sampling methods, and the necessity for advanced two-pass decoding processes. These challenges hinder the effectivity and high quality of audio synthesis, significantly in zero-shot TTS duties that require multi-lingual, multi-speaker, and multi-domain capabilities.
Researchers have tried to deal with the challenges in text-to-speech (TTS) synthesis. Conventional strategies embody concatenative techniques, which reassemble audio segments, and parametric techniques, which use acoustic parameters to synthesize speech. Finish-to-end neural TTS techniques, akin to Tacotron, TransformerTTS, and FastSpeech, simplified the method by producing mel-spectrograms instantly from textual content.
Latest developments deal with zero-shot TTS capabilities. Fashions like VALL-E deal with TTS as a conditional language activity, utilizing neural codec codes as intermediate representations. VALL-E X prolonged this method to multi-lingual eventualities. Mega-TTS proposed disentangling speech attributes for extra environment friendly modeling. Different fashions like ELLA-V, RALL-E, and VALL-E R aimed to enhance robustness and stability.
Some researchers explored non-autoregressive approaches for sooner inference, akin to SoundStorm’s parallel decoding scheme and StyleTTS 2’s diffusion mannequin. Nonetheless, these strategies typically wrestle to keep up audio high quality or effectively deal with multi-speaker, multi-lingual eventualities.
Researchers from The Chinese language College of Hong Kong and Microsoft Company current MELLE, a singular method to text-to-speech synthesis, using continuous-valued tokens primarily based on mel-spectrograms. This methodology goals to beat the constraints of discrete codec codes by instantly producing steady mel-spectrogram frames from textual content enter. The method addresses two key challenges: setting an applicable coaching goal for steady representations and enabling sampling mechanisms in steady area.
To deal with these challenges, MELLE employs regression loss with a spectrogram flux loss operate as a substitute of cross-entropy loss. This new loss operate helps mannequin the likelihood distribution of continuous-valued tokens extra successfully. Additionally, MELLE incorporates variational inference to facilitate sampling mechanisms, enhancing output variety and mannequin robustness.
The mannequin operates as a single-pass zero-shot TTS system, autoregressively predicting mel-spectrogram frames primarily based on earlier mel-spectrogram and textual content tokens. This method goals to get rid of the robustness points related to sampling discrete codec codes, doubtlessly providing improved constancy and effectivity in speech synthesis.
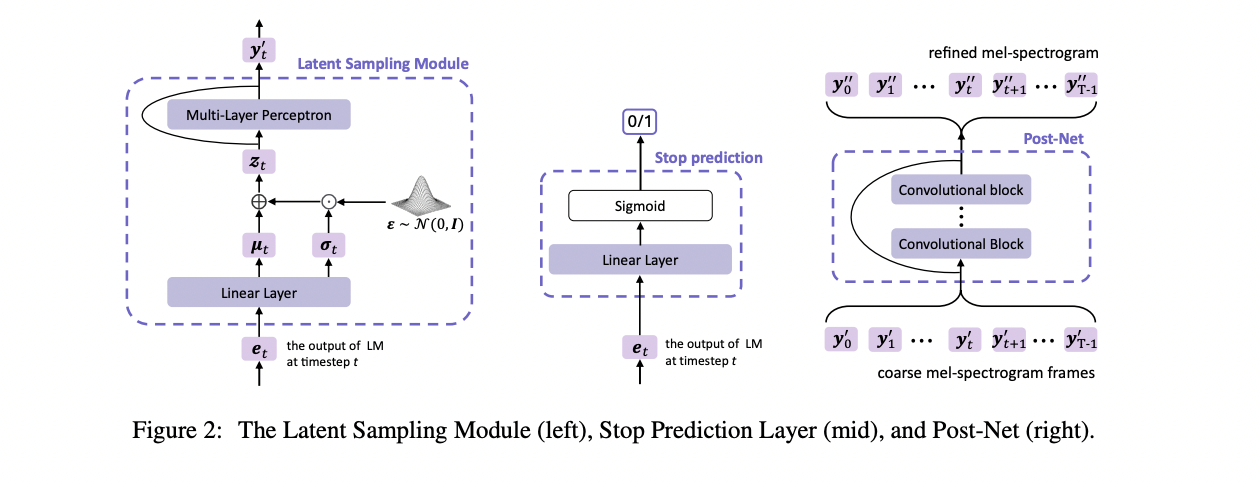
MELLE’s structure integrates a number of revolutionary parts for environment friendly text-to-speech synthesis. It employs an embedding layer, an autoregressive Transformer decoder, and a singular latent sampling module that enhances output variety. The mannequin features a cease prediction layer and a convolutional post-net for spectrogram refinement. Not like neural codec fashions, MELLE doesn’t require a separate non-autoregressive mannequin, bettering effectivity. It could generate a number of mel-spectrogram frames per step, additional enhancing efficiency. The structure concludes with a vocoder to transform the mel-spectrogram right into a waveform, providing a streamlined, single-pass method that doubtlessly surpasses earlier strategies in each high quality and effectivity.
MELLE demonstrates superior efficiency in zero-shot speech synthesis duties in comparison with VALL-E and its variants. It considerably outperforms vanilla VALL-E in robustness and speaker similarity, attaining a 47.9% relative discount in WER-H on the continuation activity and a 64.4% discount on the cross-sentence activity. Whereas VALL-E 2 reveals comparable outcomes, MELLE reveals higher robustness and speaker similarity within the continuation activity, highlighting its superior in-context studying capacity.
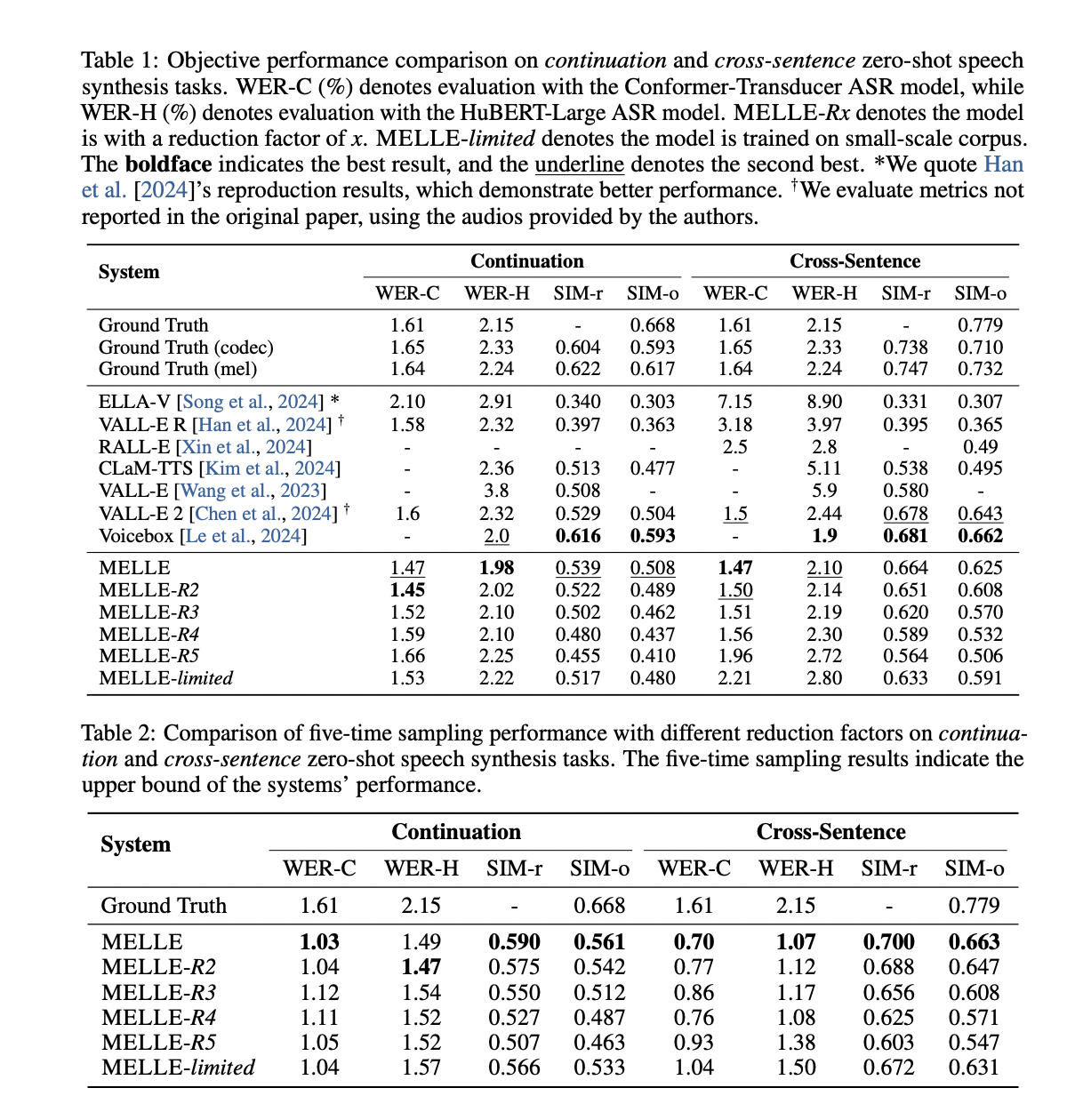
MELLE’s efficiency stays persistently excessive even with elevated discount components, permitting for sooner coaching and inference. The mannequin outperforms most up-to-date works in each robustness and speaker similarity, even with bigger discount components. MELLE-limited, educated on a smaller corpus, nonetheless surpasses VALL-E and its variants, besides VALL-E 2. Utilizing a number of sampling with a bigger discount issue can improve efficiency whereas decreasing inference time, as demonstrated by the five-time sampling outcomes, which present constant excessive robustness throughout completely different discount issue settings.
This research introduces MELLE representing a big development in zero-shot text-to-speech synthesis, introducing a steady acoustic representation-based language modeling method. By instantly predicting mel-spectrograms from textual content content material and speech prompts, it eliminates the necessity for discrete vector quantization and two-pass procedures typical of neural codec language fashions like VALL-E. The incorporation of latent sampling and spectrogram flux loss permits MELLE to supply extra various and sturdy predictions. The mannequin’s effectivity will be additional enhanced by adjusting the discount issue for sooner decoding. Notably, MELLE achieves outcomes akin to human efficiency in subjective evaluations, marking a considerable step ahead within the area of speech synthesis.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


