
Coaching large-scale language fashions presents important challenges, primarily because of the growing computational prices and power consumption as mannequin sizes develop. This problem is crucial for the development of AI analysis as a result of optimizing coaching effectivity permits for the event and deployment of extra subtle language fashions with out prohibitive useful resource necessities. Environment friendly optimization strategies can improve the efficiency and applicability of AI fashions in numerous real-world eventualities, corresponding to medical analysis and automatic customer support, by making the coaching course of extra possible and cost-effective.
Present strategies for optimizing language fashions primarily contain the Adam optimizer, recognized for its adaptive studying price capabilities. Different optimizers, like Stochastic Gradient Descent (SGD), Adafactor, and Lion, have additionally been explored. Nonetheless, these current strategies include particular limitations. As an illustration, SGD, whereas computationally less complicated, lacks the adaptive capabilities of Adam, resulting in much less secure efficiency throughout numerous hyperparameters. Adafactor, though extra memory-efficient, typically falls brief in efficiency in comparison with Adam. Lion, a more recent optimizer, exhibits promise however nonetheless lacks complete validation throughout totally different mannequin scales and architectures. These limitations spotlight the necessity for a extra strong and universally efficient optimization technique.
A crew of researchers from Harvard College and Kempner Institute at Harvard College suggest a comparative research of a number of optimization algorithms, together with Adam, SGD, Adafactor, and Lion, to establish their efficiency throughout numerous mannequin sizes and hyperparameter configurations. The revolutionary facet of this strategy lies in its complete scope—evaluating these optimizers not simply when it comes to their peak efficiency but additionally their stability throughout totally different hyperparameter settings. This twin concentrate on efficiency and stability addresses a crucial hole in current analysis, offering a nuanced understanding of every optimizer’s strengths and weaknesses. The research introduces two simplified variations of Adam: Signum, which captures the core advantages of Adam’s momentum element, and Adalayer, which isolates the consequences of layerwise preconditioning.
The analysis includes in depth experimentation utilizing autoregressive language fashions with totally different parameter scales (150m, 300m, 600m, and 1.2b). Key hyperparameters corresponding to studying charges and momentum are systematically various to evaluate their influence on optimizer efficiency. The fashions are skilled on the C4 dataset, tokenized with the T5 tokenizer, and evaluated based mostly on validation loss. The research additionally delves into particular parts of the community structure, such because the function of LayerNorm parameters and the final layer in contributing to total mannequin stability and efficiency. Detailed analyses are carried out to know how totally different layers of the community reply to varied optimization methods.
The findings point out that Adam, Adafactor, and Lion carry out comparably when it comes to each peak efficiency and stability, whereas SGD constantly underperforms. This means that practitioners can select amongst these optimizers based mostly on sensible issues like reminiscence utilization and ease of implementation, with out important loss in efficiency. Notably, the analysis additionally reveals that adaptivity is essential primarily for the final layer and LayerNorm parameters, whereas the remainder of the mannequin might be successfully skilled with less complicated strategies like SGD. This nuanced understanding of optimizer efficiency and stability throughout totally different hyperparameters and mannequin scales offers helpful insights for optimizing large-scale language fashions.
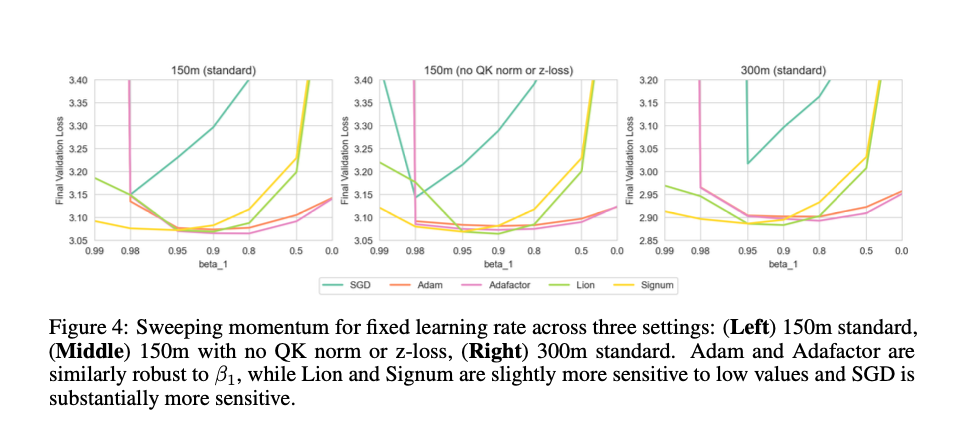
In conclusion, this proposed methodology offers a complete evaluation of optimizer efficiency and stability for language mannequin coaching. By analyzing a number of optimizers throughout numerous hyperparameter settings and mannequin scales, the research presents helpful insights that may information the selection of optimization methods in apply. This work advances the sector of AI analysis by addressing the crucial problem of environment friendly mannequin coaching, doubtlessly decreasing the computational burden and making superior language fashions extra accessible.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 46k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


