
Evaluating the efficiency of huge language mannequin (LLM) inference techniques utilizing standard metrics presents vital challenges. Metrics equivalent to Time To First Token (TTFT) and Time Between Tokens (TBT) don’t seize the whole consumer expertise throughout real-time interactions. This hole is important in functions like chat and translation, the place responsiveness immediately impacts consumer satisfaction. There’s a want for a extra nuanced analysis framework that totally encapsulates the intricacies of LLM inference to make sure optimum deployment and efficiency in real-world situations.
Present strategies for evaluating LLM inference efficiency embody TTFT, TBT, normalized latency, and Time Per Output Token (TPOT). These metrics assess varied facets of latency and throughput however fall quick in offering a complete view of the consumer expertise. For instance, TTFT and TBT give attention to particular person token latencies with out contemplating end-to-end throughput, whereas normalized metrics obscure points like inter-token jitter and scheduling delays. These limitations hinder their effectiveness in real-time functions the place sustaining a clean and constant token technology fee is essential.
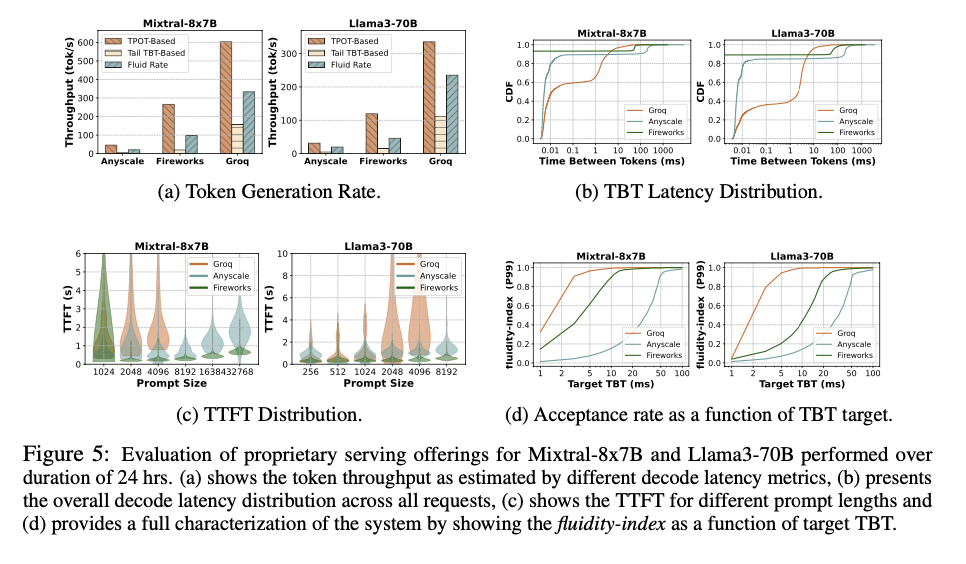
A staff of researchers from Georgia Institute of Know-how, Microsoft Analysis India, and Intel AI Lab suggest Metron, a complete efficiency analysis framework. Metron introduces novel metrics such because the fluidity-index and fluid token technology fee, which seize the nuances of real-time, streaming LLM interactions. These metrics take into account the temporal facets of token technology, making certain a extra correct reflection of user-facing efficiency. By setting token-level deadlines and measuring the fraction of deadlines met, the fluidity-index offers a exact definition of consumer expertise constraints. This strategy represents a major contribution by providing a extra correct and user-centric analysis technique.
Metron’s fluidity-index metric units deadlines for token technology primarily based on desired TTFT and TBT values, adjusting these primarily based on immediate size and noticed system efficiency. This technique accounts for scheduling delays and variable token technology charges, making certain clean output. The framework evaluates each open-source and proprietary LLM inference techniques, making use of the fluidity-index to measure the proportion of deadlines met and dynamically adjusting deadlines primarily based on real-time efficiency. This technique affords a complete view of the system’s capability to deal with consumer requests with out compromising responsiveness.
Metron offers a extra correct analysis of LLM inference techniques in comparison with standard metrics. The fluidity-index and fluid token technology fee reveal vital variations in consumer expertise that aren’t captured by TTFT or TBT alone. For instance, the analysis of techniques like vLLM and Sarathi-Serve demonstrated that Sarathi-Serve achieved fewer deadline misses and better fluidity. The findings present that Sarathi-Serve maintained a fluidity-index > 0.9 for 99% of requests, reaching a throughput of 600 tokens per second, whereas vLLM confirmed a 3x worse tail TBT on account of technology stalls. This demonstrates Metron’s effectiveness in revealing efficiency variations and making certain higher consumer experiences in real-world functions.
In conclusion, this proposed technique, Metron, introduces a novel analysis framework, together with the fluidity-index and fluid token technology fee metrics, to raised assess LLM inference efficiency. This strategy overcomes the restrictions of standard metrics by offering a user-centric analysis that captures the intricacies of real-time token technology. The findings display Metron’s effectiveness in revealing efficiency variations and its potential impression on enhancing LLM serving frameworks, making certain higher consumer experiences in real-world functions.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our 46k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.


