
Laptop imaginative and prescient allows machines to interpret & perceive visible info from the world. This encompasses a wide range of duties, corresponding to picture classification, object detection, and semantic segmentation. Improvements on this space have been propelled by growing superior neural community architectures, significantly Convolutional Neural Networks (CNNs) and, extra not too long ago, Transformers. These fashions have demonstrated important potential in processing visible information. Nonetheless, there stays a steady want for enhancements of their means to stability computational effectivity with capturing each native and world visible contexts.
A central problem in laptop imaginative and prescient is the environment friendly modeling and processing of visible information. This requires understanding each native particulars and broader contextual info inside photos. Conventional fashions typically need assistance with this stability. CNNs, whereas environment friendly at dealing with native spatial relationships, might overlook broader contextual info. However, Transformers, which leverage self-attention mechanisms to seize world context, will be computationally intensive attributable to their quadratic complexity relative to sequence size. This trade-off between effectivity and context-capture functionality has considerably hindered the advancing imaginative and prescient fashions’ efficiency.
Present approaches primarily make the most of CNNs for his or her effectiveness in dealing with native spatial relationships. Nonetheless, these fashions might solely partially seize the broader contextual info obligatory for extra complicated imaginative and prescient duties. Transformers have been utilized to imaginative and prescient duties to deal with this challenge, using self-attention mechanisms to reinforce the understanding of the worldwide context. Regardless of these developments, each CNNs and Transformers have inherent limitations. CNNs can miss the broader context, whereas Transformers are computationally costly and difficult to coach and deploy effectively.
Researchers at NVIDIA have launched MambaVision, a novel hybrid mannequin that mixes the strengths of Mamba and Transformer architectures. This new method integrates CNN-based layers with Transformer blocks to reinforce the modeling capability for imaginative and prescient purposes. The MambaVision household consists of numerous mannequin configurations to fulfill totally different design standards and utility wants, offering a versatile and highly effective device for numerous imaginative and prescient duties. The introduction of MambaVision represents a big step ahead within the improvement of hybrid fashions for laptop imaginative and prescient.
MambaVision employs a hierarchical structure divided into 4 levels. The preliminary levels use CNN layers for speedy function extraction, capitalizing on their effectivity in processing high-resolution options. The later levels incorporate MambaVision and Transformer blocks to successfully seize each brief—and long-range dependencies. This revolutionary design permits the mannequin to deal with world context extra effectively than conventional approaches. The redesigned Mamba blocks, which now embrace self-attention mechanisms, are central to this enchancment, enabling the mannequin to course of visible information with better accuracy and throughput.
The efficiency of MambaVision is notable, attaining state-of-the-art outcomes on the ImageNet-1K dataset. For instance, the MambaVision-B mannequin achieves a Prime-1 accuracy of 84.2%, surpassing different main fashions corresponding to ConvNeXt-B and Swin-B, which gained 83.8% and 83.5%, respectively. Along with its excessive accuracy, MambaVision demonstrates superior picture throughput, with the MambaVision-B mannequin processing photos considerably sooner than its opponents. In downstream duties like object detection and semantic segmentation on the MS COCO and ADE20K datasets, MambaVision outperforms comparably-sized backbones, showcasing its versatility and effectivity. For example, MambaVision fashions present enhancements in field AP and masks AP metrics, attaining 46.4 and 41.8, respectively, greater than these achieved by fashions like ConvNeXt-T and Swin-T.
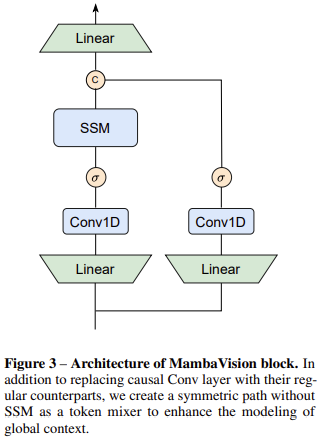
A complete ablation research helps these findings, demonstrating the effectiveness of MambaVision’s design decisions. The researchers improved accuracy and picture throughput by redesigning the Mamba block to be extra appropriate for imaginative and prescient duties. The research explored numerous integration patterns of Mamba and Transformer blocks, revealing that incorporating self-attention blocks within the ultimate layers considerably enhances the mannequin’s means to seize world context and long-range spatial dependencies. This design produces a richer function illustration and higher efficiency throughout numerous imaginative and prescient duties.

In conclusion, MambaVision represents a big development in imaginative and prescient modeling by combining the strengths of CNNs and Transformers right into a single, hybrid structure. This method successfully addresses the restrictions of present fashions by enhancing understanding of native and world contexts, resulting in superior efficiency in numerous imaginative and prescient duties. The outcomes of this research point out a promising path for future developments in laptop imaginative and prescient, doubtlessly setting a brand new normal for hybrid imaginative and prescient fashions.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to hitch our 46k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


