
Scientific discovery has been a cornerstone of human development for hundreds of years, historically counting on handbook processes. Nonetheless, the emergence of enormous language fashions (LLMs) with superior reasoning capabilities and the power to work together with exterior instruments and brokers has opened up new potentialities for autonomous discovery methods. The problem lies in creating a completely autonomous system able to producing and verifying hypotheses throughout the realm of data-driven discovery. Whereas current research have proven promising outcomes on this path, the total extent of LLMs’ potential in scientific discovery stays unsure. Researchers at the moment are confronted with the duty of exploring and increasing the capabilities of those AI methods to revolutionize the scientific course of, doubtlessly accelerating the tempo of discovery and innovation throughout numerous fields.
Earlier makes an attempt at automated data-driven discovery have ranged from early methods like Bacon, which fitted equations to idealized knowledge, to extra superior options like AlphaFold, able to dealing with complicated real-world issues. Nonetheless, these methods typically relied on task-specific datasets and pre-built pipelines. AutoML instruments, corresponding to Scikit and cloud-based options, have made strides in automating machine studying workflows, however their datasets are primarily used for mannequin coaching fairly than open-ended discovery duties. Equally, statistical evaluation datasets and software program packages like Tableaux, SAS, and R assist knowledge evaluation however are restricted in scope. The QRData dataset represents a step in the direction of exploring LLM capabilities in statistical and causal evaluation, nevertheless it focuses on well-defined questions with distinctive, primarily numeric solutions. These current approaches, whereas priceless, want to offer a complete resolution for automating your complete discovery course of, together with ideation, semantic reasoning, and pipeline design.
Researchers from the Allen Institute for AI, OpenLocus, and the College of Massachusetts Amherst suggest DISCOVERYBENCH which goals to systematically consider the capabilities of state-of-the-art massive language fashions (LLMs) in automated data-driven discovery. This benchmark addresses the challenges of range in real-world data-driven discovery throughout numerous domains by introducing a practical formalization. It defines discovery duties as trying to find relationships between variables inside a particular context, the place the outline of those components might indirectly correspond to the dataset’s language. This method permits for systematic and reproducible analysis of a variety of real-world issues by using key aspects of the invention course of.
DISCOVERYBENCH distinguishes itself from earlier datasets for statistical evaluation or AutoML by incorporating scientific semantic reasoning. This contains deciding on applicable evaluation methods for particular domains, knowledge cleansing and normalization, and mapping aim phrases to dataset variables. The duties sometimes require multistep workflows, addressing the broader data-driven discovery pipeline fairly than focusing solely on statistical evaluation. This complete method makes DISCOVERYBENCH the primary large-scale dataset to discover LLMs’ capability for your complete discovery course of.
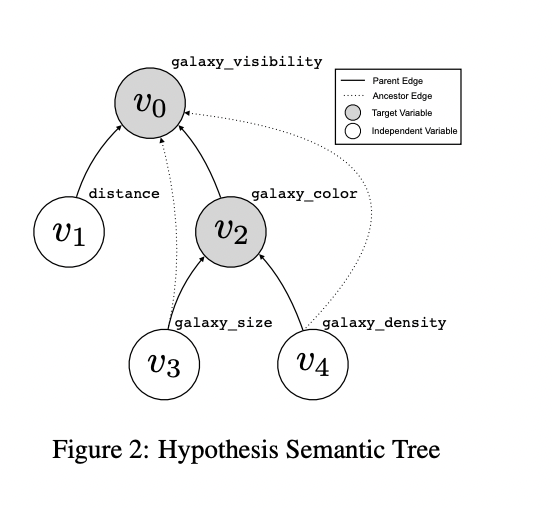
On this methodology, researchers start by formalizing data-driven discovery by introducing a structured method to speculation illustration and analysis. It defines hypotheses as declarative sentences verifiable by datasets, breaking them down into contexts, variables, and relationships. The important thing innovation is the Speculation Semantic Tree, a hierarchical construction representing complicated hypotheses with interconnected variables. This tree permits for encoding a number of hypotheses inside a single construction. The strategy additionally formalizes activity datasets as collections of tuples supporting a number of speculation semantic timber, with various levels of observability. This framework offers a versatile but rigorous method to representing and evaluating complicated discovery issues, enabling systematic evaluation of automated discovery methods.
DISCOVERYBENCH consists of two important elements: DB-REAL and DB-SYNTH. DB-REAL encompasses real-world hypotheses and workflows derived from printed scientific papers throughout six domains: sociology, biology, humanities, economics, engineering, and meta-science. It contains duties that usually require evaluation of a number of datasets, with workflows starting from fundamental knowledge preparation to superior statistical analyses. DB-SYNTH, however, is a synthetically generated benchmark that enables for managed mannequin evaluations. It makes use of massive language fashions to generate numerous domains, assemble semantic speculation timber, create artificial datasets, and formulate discovery duties of various issue. This twin method permits DISCOVERYBENCH to seize each the complexity of real-world discovery issues and the systematic variation wanted for complete mannequin analysis.

The research evaluates a number of discovery brokers powered by totally different language fashions (GPT-4o, GPT-4p, and Llama-3-70B) on the DISCOVERYBENCH dataset. The brokers embody CodeGen, ReAct, DataVoyager, Reflexion (Oracle), and NoDataGuess. Outcomes present that general efficiency is low throughout all agent-LLM pairs for each DB-REAL and DB-SYNTH, highlighting the benchmark’s difficult nature. Surprisingly, superior reasoning prompts (React) and planning with self-criticism (DataVoyager) don’t considerably outperform the easy CodeGen agent. Nonetheless, Reflexion (Oracle), which makes use of suggestions for enchancment, exhibits notable positive factors over CodeGen. The research additionally reveals that non-reflexion brokers primarily remedy the best situations, and efficiency on DB-REAL and DB-SYNTH is comparable, validating the artificial benchmark’s skill to seize real-world complexities.
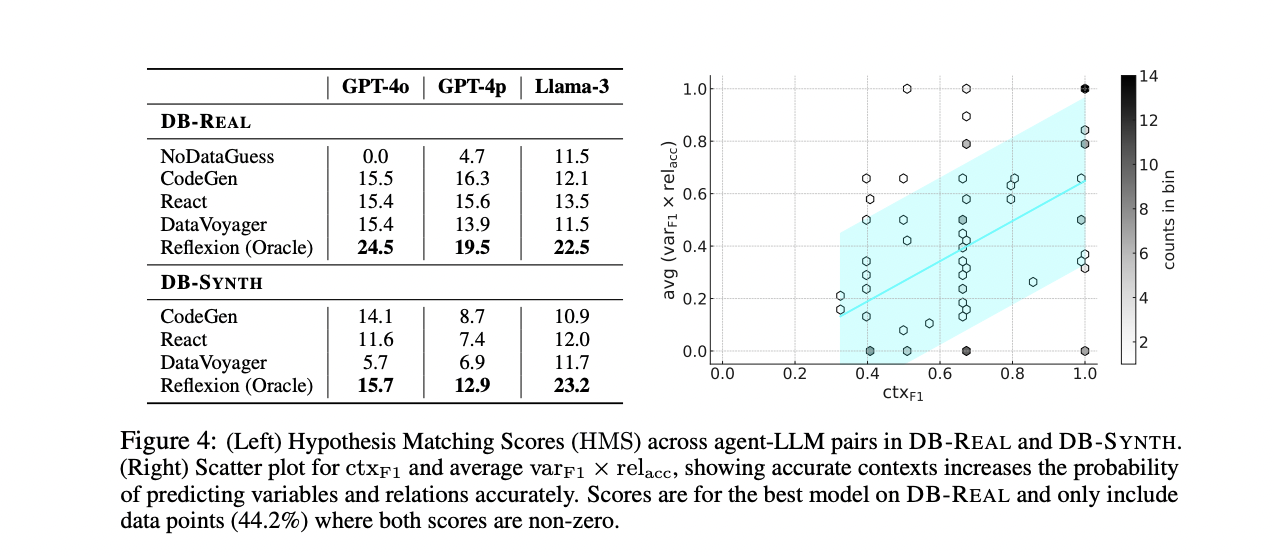
DISCOVERYBENCH represents a major development in evaluating automated data-driven discovery methods. This complete benchmark contains 264 real-world discovery duties derived from printed scientific workflows, complemented by 903 synthetically generated duties designed to evaluate discovery brokers at numerous issue ranges. Regardless of using state-of-the-art reasoning frameworks powered by superior massive language fashions, the best-performing agent solely achieves a 25% success charge. This modest efficiency underscores the difficult nature of automated scientific discovery and highlights the appreciable room for enchancment on this subject. By offering this well timed and strong analysis framework, DISCOVERYBENCH goals to stimulate elevated curiosity and analysis efforts in creating extra dependable and reproducible autonomous scientific discovery methods utilizing massive generative fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


