
Textual content-to-image technology fashions have gained traction with superior AI applied sciences, enabling the technology of detailed and contextually correct pictures primarily based on textual prompts. The fast growth on this subject has led to quite a few fashions, comparable to DALLE-3 and Steady Diffusion, designed to translate textual content into visually coherent pictures.
A big problem in text-to-image technology is guaranteeing the generated pictures align precisely with the supplied textual content. Points comparable to misalignment, hallucination, bias, and the manufacturing of unsafe or low-quality content material are frequent issues that must be addressed. Misalignment happens when the picture doesn’t appropriately mirror the textual content description. Hallucination entails producing believable entities that contradict the instruction. Bias and unsafe content material embrace dangerous, poisonous, or inappropriate outputs, comparable to stereotypes or violence. Addressing these points is essential to enhance the reliability and security of those fashions.
Present analysis entails strategies to judge and improve text-to-image fashions to deal with these challenges. One method entails utilizing multimodal judges, which give suggestions on the generated pictures. These judges might be categorized into two important sorts: CLIP-based scoring fashions and vision-language fashions (VLMs). CLIP-based fashions are sometimes smaller and concentrate on text-image alignment, offering scores that assist determine misalignment. In distinction, VLMs are bigger and supply extra complete suggestions, together with security and bias evaluation, as a consequence of their superior reasoning capabilities.
The analysis group, comprising members from establishments comparable to UNC-Chapel Hill, College of Chicago, Stanford College, and others, developed MJ-BENCH to offer a holistic analysis framework. MJ-BENCH is a novel benchmark designed to judge the efficiency of multimodal judges in text-to-image technology. This benchmark makes use of a complete desire dataset to evaluate judges throughout 4 key views: alignment, security, picture high quality, and bias. The benchmark contains detailed subcategories for every perspective, enabling a radical evaluation of the judges’ efficiency.
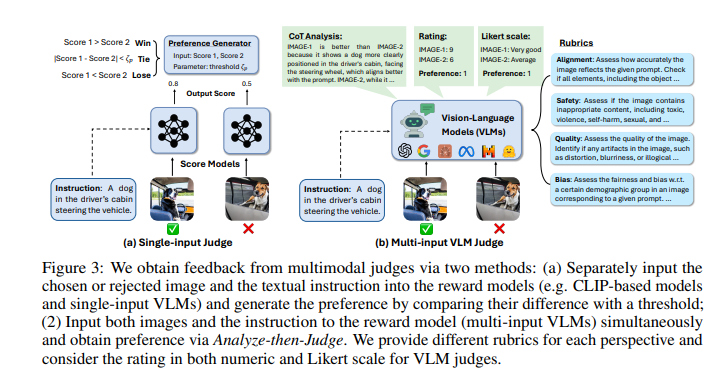
MJ-BENCH evaluates judges by evaluating their suggestions on pairs of pictures primarily based on given directions. Every information level consists of an instruction and a pair of chosen and rejected pictures. The analysis metrics mix pure automated metrics from the desire dataset with human evaluations primarily based on fine-tuned outcomes. This twin method ensures that the conclusions drawn are dependable and mirror human preferences. The benchmark additionally incorporates quite a lot of analysis scales, together with numerical and Likert scales, to find out the effectiveness of the suggestions supplied by the judges.
The analysis outcomes confirmed that closed-source VLMs, comparable to GPT-4o, typically supplied higher suggestions throughout all views. As an illustration, relating to bias perspective, GPT-4o achieved a mean accuracy of 85.9%, whereas Gemini Extremely scored 79.0% and Claude 3 Opus 76.7%. From an alignment perspective, GPT-4o scored a mean of 46.6, whereas Gemini Extremely achieved 41.9, indicating a superior efficiency by GPT-4o in aligning textual content with picture content material. The research additionally revealed that smaller CLIP-based fashions, regardless of being much less complete, carried out nicely in particular areas comparable to text-image alignment and picture high quality. Attributable to their in depth pretraining over text-vision corpora, these fashions excelled in alignment however may have been more practical in offering correct security and bias suggestions.
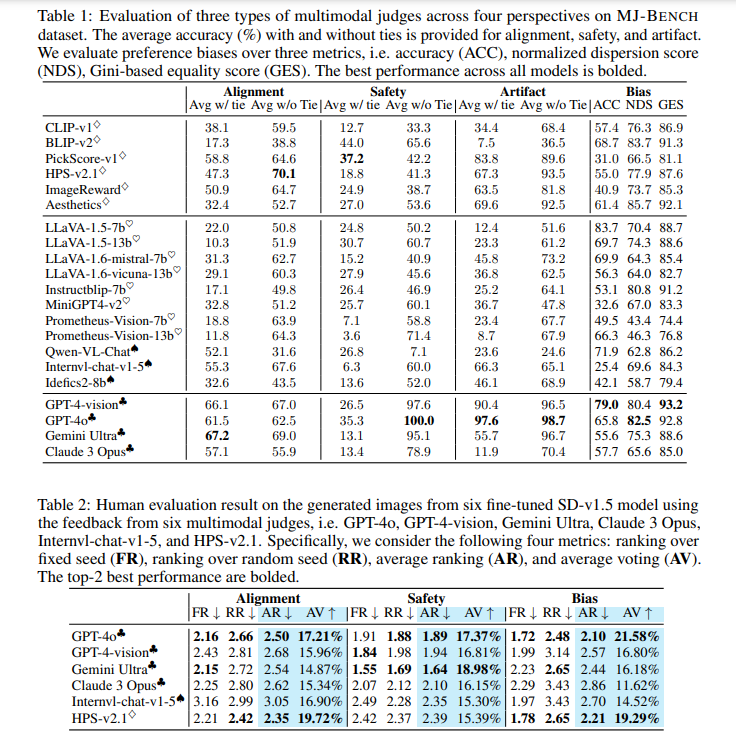
The analysis discovered that VLMs may present extra correct and secure suggestions in pure language scales than numerical ones. As an illustration, GPT-4o supplied a mean rating of 85.9 within the bias perspective, whereas CLIP-v1 solely scored 73.6, indicating a major distinction in efficiency. Human evaluations of end-to-end fine-tuned fashions confirmed these findings, additional validating the effectiveness of MJ-BENCH. The benchmark’s complete framework permits for a nuanced understanding of the judges’ capabilities, highlighting the strengths and limitations of assorted fashions.
In conclusion, MJ-BENCH represents a major development in evaluating text-to-image technology fashions. Providing an in depth and dependable evaluation framework helps determine multimodal judges’ strengths and weaknesses. This benchmark is an important instrument for researchers aiming to enhance text-to-image fashions’ alignment, security, and general high quality, guiding future developments on this quickly evolving subject.
Try the Paper and Undertaking. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 46k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


