
Giant language fashions (LLMs) have gained vital consideration for his or her spectacular efficiency throughout varied duties, from summarizing information to writing code and answering trivia questions. Their effectiveness extends to real-world functions, with fashions like GPT-4 efficiently passing authorized and medical licensing exams. Nevertheless, LLMs face two crucial challenges: hallucination and efficiency disparities. Hallucination, the place LLMs generate believable however inaccurate textual content, poses dangers in factual recall duties. Efficiency disparities manifest as inconsistent reliability throughout totally different subsets of inputs, typically linked to delicate attributes like race, gender, or language. These points underscore the necessity for continued improvement of numerous benchmarks to evaluate LLM reliability and establish potential equity issues. Creating complete benchmarks is essential not just for evaluating general efficiency but in addition for quantifying and addressing efficiency disparities, in the end working in direction of constructing fashions that carry out equitably throughout all consumer teams.
Present analysis on LLMs’ factual recall has proven blended outcomes, with fashions demonstrating some proficiency but in addition liable to fabrication. Research have linked accuracy to entity reputation however centered primarily on general error charges quite than geographic disparities. Whereas some researchers have explored geographic data recall, these efforts have been restricted in scope. Within the broader context of AI bias, disparities throughout varied demographics have been noticed in numerous domains. Nevertheless, a complete, systematic examination of country-wise disparities in LLM factual recall has been missing, highlighting the necessity for a extra strong and geographically delicate analysis strategy.
Researchers from the College of Maryland and Michigan State College suggest a sturdy benchmark referred to as WorldBench to analyze potential geographic disparities in Giant Language Fashions’ (LLMs) factual recall capabilities. This strategy goals to find out if LLMs display various ranges of accuracy when answering questions on totally different components of the world. WorldBench makes use of country-specific indicators from the World Financial institution, using an automatic, indicator-agnostic prompting and parsing pipeline. The benchmark incorporates 11 numerous indicators for roughly 200 nations, producing 2,225 questions per LLM. The research evaluates 20 state-of-the-art LLMs launched in 2023, together with each open-source fashions like Llama-2 and Vicuna, in addition to non-public business fashions equivalent to GPT-4 and Gemini. This complete analysis technique permits for a scientific evaluation of LLMs’ efficiency throughout varied geographic areas and earnings teams.
WorldBench is constructed utilizing statistics from the World Financial institution, a world group monitoring quite a few improvement indicators throughout practically 200 nations. This strategy gives a number of distinctive benefits: equitable illustration of all nations, assured knowledge high quality from a good supply, and adaptability in indicator choice. The benchmark incorporates 11 numerous indicators, leading to 2,225 questions reflecting a median of 202 nations per indicator.
The analysis course of entails a standardized prompting technique utilizing a template with base directions and an instance. An automatic parsing system extracts numeric values from LLM outputs, with absolute relative error used because the comparability metric. The pipeline’s effectiveness was validated by handbook inspection research, confirming its completeness and correctness. Groundtruth values are decided by averaging statistics over the previous three years to maximise nation inclusion. This complete methodology permits systematic evaluation of LLM efficiency throughout varied geographic areas and earnings teams.
The research reveals vital geographic disparities in LLM factual recall throughout totally different areas and earnings teams. On common, North America and Europe & Central Asia skilled the bottom error charges (0.316 and 0.321 respectively), whereas Sub-Saharan Africa had the very best (0.461), about 1.5 occasions increased than North America. Error charges steadily elevated as nation earnings ranges decreased, with high-income nations having the bottom error (0.346) and low-income nations the very best (0.480).
On a per-country foundation, disparities had been much more pronounced. The 15 nations with the bottom error charges had been all high-income, largely European, whereas the 15 with the very best had been all low-income. Strikingly, error charges practically tripled between these two teams. These disparities had been constant throughout all 20 LLMs evaluated and all 11 indicators used, with noticed disparities far exceeding these anticipated from random nation categorization. Even the best-performing LLMs confirmed substantial room for enchancment, with the bottom imply absolute relative error at 0.19 and most fashions close to 0.4.
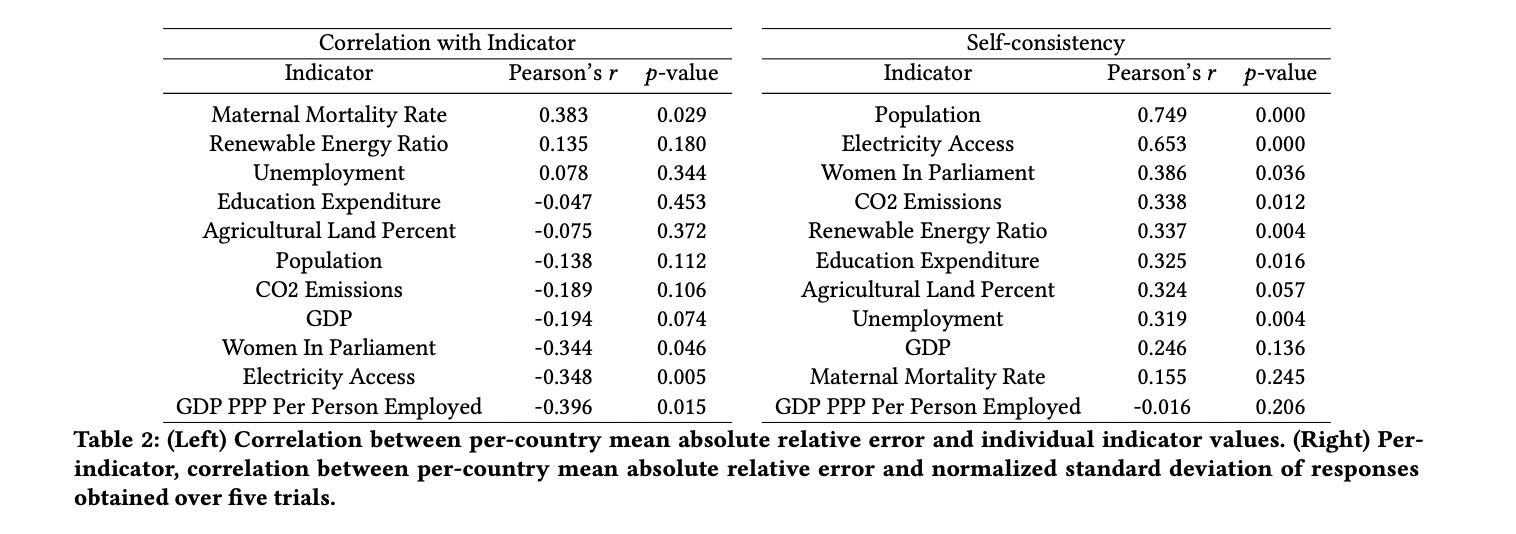
This research presents WorldBench, a sturdy benchmark for quantifying geographic disparities in LLM factual recall, revealing pervasive and constant biases throughout 20 evaluated LLMs. The research demonstrates that Western and higher-income nations persistently expertise decrease error charges in factual recall duties. By using World Financial institution knowledge, WorldBench gives a versatile and repeatedly up to date framework for assessing these disparities. This benchmark serves as a worthwhile device for figuring out and addressing geographic biases in LLMs, probably aiding within the improvement of future fashions that carry out equitably throughout all areas and earnings ranges. In the end, WorldBench goals to contribute to the creation of extra globally inclusive and truthful language fashions that may successfully serve customers from all components of the world.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 46k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


