
Pure language processing (NLP) in synthetic intelligence focuses on enabling machines to grasp and generate human language. This discipline encompasses a wide range of duties, together with language translation, sentiment evaluation, and textual content summarization. Lately, vital developments have been made, resulting in the event of enormous language fashions (LLMs) that may course of huge quantities of textual content. These developments have opened up prospects for advanced duties resembling long-context summarization and retrieval-augmented era (RAG).
One of many main challenges in NLP is successfully evaluating the efficiency of LLMs on duties that require processing lengthy contexts. Conventional duties, resembling Needle-in-a-Haystack, don’t present the complexity wanted to distinguish the capabilities of the most recent fashions. Moreover, evaluating the standard of outputs for these duties is difficult as a result of want for high-quality reference summaries and dependable automated metrics. This hole in analysis strategies hinders the correct evaluation of contemporary LLMs.
Current strategies for evaluating summarization efficiency usually deal with short-input, single-document settings. These strategies rely closely on low-quality reference summaries, which correlate poorly with human judgments. Though there are some benchmarks for long-context fashions, resembling Needle-in-a-Haystack and guide summarization, they should sufficiently check the total capabilities of state-of-the-art LLMs. This limitation underscores the necessity for extra complete and dependable analysis strategies.
Researchers at Salesforce AI Analysis launched a novel analysis technique known as the “Abstract of a Haystack” (SummHay) activity. This technique goals to judge long-context fashions and RAG programs extra successfully. The researchers created artificial Haystacks of paperwork, guaranteeing particular insights had been repeated throughout these paperwork. The SummHay activity requires programs to course of these Haystacks, generate summaries that precisely cowl the related insights, and cite the supply paperwork. This strategy offers a reproducible and complete framework for analysis.
The methodology includes a number of detailed steps. First, researchers generate Haystacks of paperwork on particular subjects, guaranteeing sure insights are repeated throughout these paperwork. Every Haystack sometimes accommodates round 100 paperwork, totaling roughly 100,000 tokens. The paperwork are fastidiously designed to incorporate particular insights categorized into varied subtopics. As an example, subtopics may encompass research methods and stress administration in a subject about examination preparation, every expanded into distinct insights.
As soon as the Haystacks are generated, the SummHay activity is framed as a query-focused summarization activity. Programs are given queries associated to the subtopics and should generate summaries in bullet-point format. Every abstract should cowl the related insights and cite the supply paperwork exactly. The analysis protocol then assesses the summaries on two major facets: protection of the anticipated insights and the standard of the citations. This rigorous course of ensures excessive reproducibility and accuracy within the analysis.
Relating to efficiency, the analysis group performed a large-scale analysis of 10 LLMs and 50 RAG programs. Their findings indicated that the SummHay activity stays a big problem for present programs. For instance, even when programs had been supplied with oracle indicators of doc relevance, they lagged behind human efficiency by over 10 factors on a joint rating. Particularly, long-context LLMs like GPT-4o and Claude 3 Opus scored beneath 20% on SummHay with no retriever. The research additionally highlighted the trade-offs between RAG programs and long-context fashions. RAG programs sometimes enhance quotation high quality on the expense of perception protection.
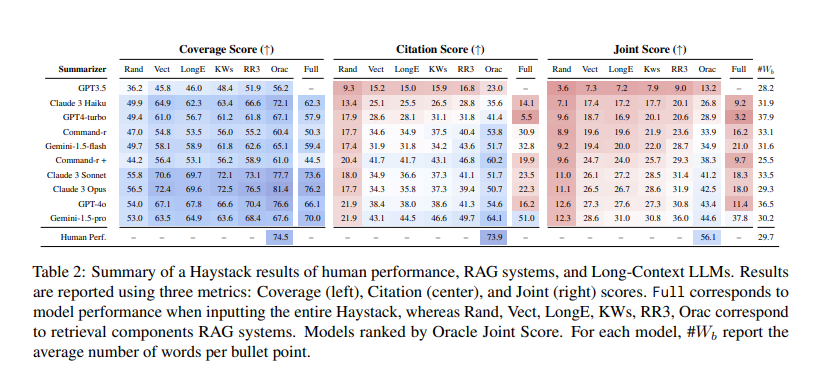
The efficiency analysis revealed that present fashions battle to fulfill human efficiency ranges. As an example, when utilizing a complicated RAG element like Cohere’s Rerank3, the end-to-end efficiency on the SummHay activity confirmed substantial enhancements. Nevertheless, even with these enhancements, fashions like Claude 3 Opus and GPT-4o might solely obtain a joint rating of round 36%, considerably beneath the estimated human efficiency of 56%. This hole underscores the necessity for additional developments within the discipline.
In conclusion, the analysis performed by Salesforce AI Analysis addresses a essential hole in evaluating long-context LLMs and RAG programs. The SummHay benchmark offers a sturdy framework for assessing the capabilities of those programs, highlighting vital challenges and areas for enchancment. Regardless of present programs underperforming in comparison with human benchmarks, this analysis paves the way in which for future developments that would ultimately match or surpass human efficiency in long-context summarization.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


