
Language modeling in synthetic intelligence focuses on growing methods that may perceive, interpret, and generate human language. This discipline encompasses numerous functions, comparable to machine translation, textual content summarization, and conversational brokers. Researchers purpose to create fashions that mimic human language skills, permitting for seamless interplay between people and machines. The developments on this discipline have led to the event of more and more advanced and huge fashions that require substantial computational assets.
The rising complexity and measurement of huge language fashions (LLMs) end in vital coaching and inference prices. These prices come up from the need to encode huge quantities of data into mannequin parameters, that are each resource-intensive and computationally costly. Because the demand for extra highly effective fashions grows, the problem of managing these prices turns into extra pronounced. Addressing this downside is essential for the sustainable growth of language modeling applied sciences.
Present strategies to mitigate these prices contain optimizing numerous facets of LLMs, comparable to their structure, knowledge high quality, and parallelization. Retrieval-augmented era (RAG) fashions, as an example, use exterior information bases to cut back the load on mannequin parameters. Nonetheless, these fashions nonetheless rely closely on giant parameter sizes, which limits their effectivity. Different approaches embrace enhancing knowledge high quality and utilizing superior {hardware}, however these options solely partially deal with the underlying difficulty of excessive computational prices.
Researchers from the Institute for Superior Algorithms Analysis in Shanghai, Moqi Inc., and the Middle for Machine Studying Analysis at Peking College have launched the Reminiscence3 mannequin. This novel strategy incorporates specific reminiscence into LLMs. This mannequin externalizes a good portion of data, permitting the LLM to take care of a smaller parameter measurement. Introducing specific reminiscence represents a paradigm shift in how language fashions retailer and retrieve information.
Reminiscence3 makes use of specific reminiscences, that are cheaper to retailer and recall than conventional mannequin parameters. This design features a reminiscence sparsification mechanism and a two-stage pretraining scheme to facilitate environment friendly reminiscence formation. The mannequin converts texts into specific reminiscences, which might be retrieved throughout inference, decreasing total computational prices. The Reminiscence3 structure is designed to be suitable with current Transformer-based LLMs, requiring minimal fine-tuning. This adaptability ensures that the Reminiscence3 mannequin might be extensively adopted with out intensive system modifications. The information base includes 1.1 × 108 textual content chunks, every with a size of as much as 128 tokens, effectively saved and processed.
The Reminiscence3 mannequin, with 2.4 billion non-embedding parameters, outperformed bigger LLMs and RAG fashions. It achieved higher benchmark efficiency, demonstrating superior effectivity and accuracy. Particularly, Reminiscence3 confirmed a decoding pace greater than RAG fashions, because it didn’t depend on intensive textual content retrieval processes. Moreover, the efficiency on skilled duties, which concerned high-frequency retrieval of specific reminiscences, showcased the mannequin’s robustness and adaptableness to numerous functions. The mixing of specific reminiscences considerably lowered the computational load, permitting for sooner and extra environment friendly processing.
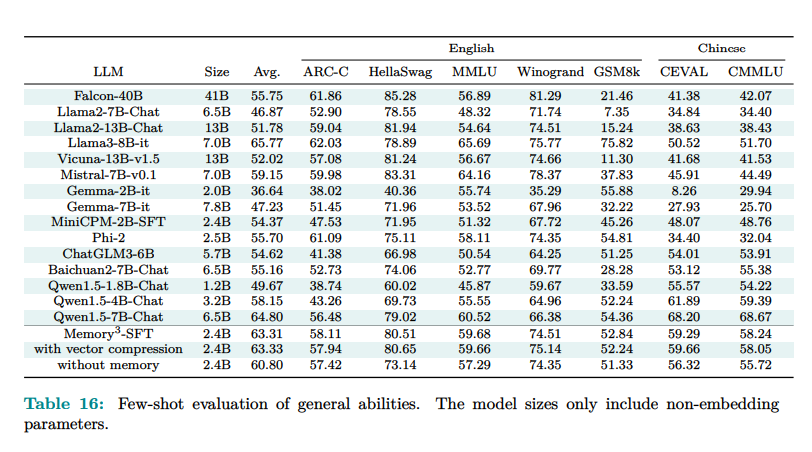
The Reminiscence3 mannequin demonstrated spectacular outcomes. It confirmed a 2.51% increase in common scores resulting from specific reminiscence in comparison with fashions with out this characteristic. In particular duties, the Reminiscence3 mannequin scored 83.3 on HellaSwag and 80.4 on BoolQ, surpassing a bigger 9.1B parameter mannequin, which scored 70.6 and 70.7, respectively. The mannequin’s decoding pace was 35.2% slower with out utilizing reminiscence, indicating environment friendly reminiscence use. Furthermore, the specific reminiscence mechanism lowered the entire reminiscence storage requirement from 7.17PB to 45.9TB, making it extra sensible for large-scale functions.
To conclude, the Reminiscence3 mannequin represents a major development in decreasing the associated fee and complexity of coaching and working giant language fashions. The researchers supply a extra environment friendly, scalable answer that maintains excessive efficiency and accuracy by externalizing some information into specific reminiscences. This modern strategy addresses the urgent difficulty of computational prices in language modeling, paving the best way for extra sustainable and accessible AI applied sciences.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


