
Code embeddings are a transformative method to characterize code snippets as dense vectors in a steady area. These embeddings seize the semantic and practical relationships between code snippets, enabling highly effective functions in AI-assisted programming. Just like phrase embeddings in pure language processing (NLP), code embeddings place related code snippets shut collectively within the vector area, permitting machines to grasp and manipulate code extra successfully.
What are Code Embeddings?
Code embeddings convert complicated code constructions into numerical vectors that seize the that means and performance of the code. Not like conventional strategies that deal with code as sequences of characters, embeddings seize the semantic relationships between elements of the code. That is essential for varied AI-driven software program engineering duties, comparable to code search, completion, bug detection, and extra.
For instance, think about these two Python features:
def add_numbers(a, b):
return a + b
def sum_two_values(x, y):
outcome = x + y
return outcome
Whereas these features look totally different syntactically, they carry out the identical operation. A very good code embedding would characterize these two features with related vectors, capturing their practical similarity regardless of their textual variations.
How are Code Embeddings Created?
There are totally different strategies for creating code embeddings. One widespread method includes utilizing neural networks to study these representations from a big dataset of code. The community analyzes the code construction, together with tokens (key phrases, identifiers), syntax (how the code is structured), and doubtlessly feedback to study the relationships between totally different code snippets.
Let’s break down the method:
- Code as a Sequence: First, code snippets are handled as sequences of tokens (variables, key phrases, operators).
- Neural Community Coaching: A neural community processes these sequences and learns to map them to fixed-size vector representations. The community considers elements like syntax, semantics, and relationships between code parts.
- Capturing Similarities: The coaching goals to place related code snippets (with related performance) shut collectively within the vector area. This enables for duties like discovering related code or evaluating performance.
This is a simplified Python instance of the way you may preprocess code for embedding:
import ast
def tokenize_code(code_string):
tree = ast.parse(code_string)
tokens = []
for node in ast.stroll(tree):
if isinstance(node, ast.Identify):
tokens.append(node.id)
elif isinstance(node, ast.Str):
tokens.append('STRING')
elif isinstance(node, ast.Num):
tokens.append('NUMBER')
# Add extra node sorts as wanted
return tokens
# Instance utilization
code = """
def greet(identify):
print("Hey, " + identify + "!")
"""
tokens = tokenize_code(code)
print(tokens)
# Output: ['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']
This tokenized illustration can then be fed right into a neural community for embedding.
Present Approaches to Code Embedding
Present strategies for code embedding will be categorised into three essential classes:
Token-Based mostly Strategies
Token-based strategies deal with code as a sequence of lexical tokens. Methods like Time period Frequency-Inverse Doc Frequency (TF-IDF) and deep studying fashions like CodeBERT fall into this class.
Tree-Based mostly Strategies
Tree-based strategies parse code into summary syntax bushes (ASTs) or different tree constructions, capturing the syntactic and semantic guidelines of the code. Examples embody tree-based neural networks and fashions like code2vec and ASTNN.
Graph-Based mostly Strategies
Graph-based strategies assemble graphs from code, comparable to management movement graphs (CFGs) and knowledge movement graphs (DFGs), to characterize the dynamic conduct and dependencies of the code. GraphCodeBERT is a notable instance.
TransformCode: A Framework for Code Embedding
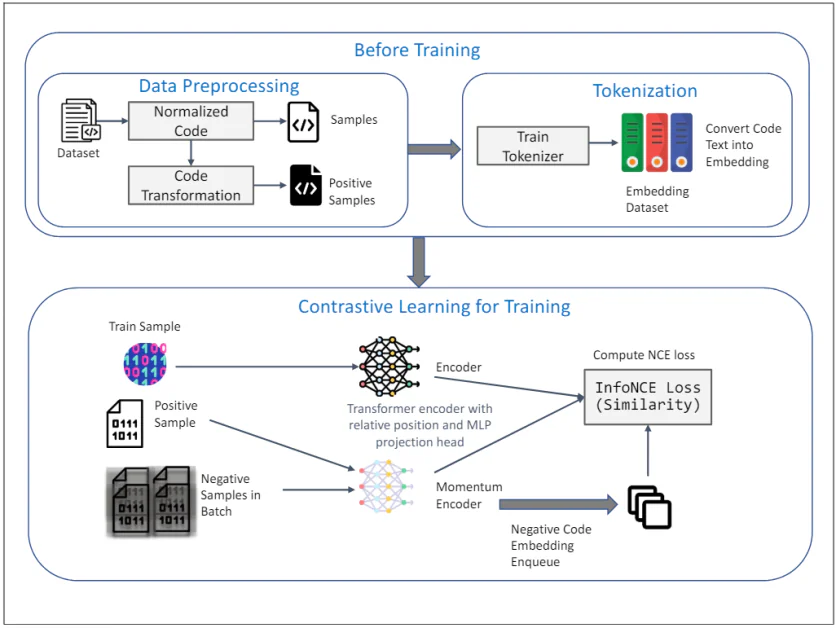
TransformCode: Unsupervised studying of code embedding
TransformCode is a framework that addresses the restrictions of present strategies by studying code embeddings in a contrastive studying method. It’s encoder-agnostic and language-agnostic, that means it might probably leverage any encoder mannequin and deal with any programming language.
The diagram above illustrates the framework of TransformCode for unsupervised studying of code embedding utilizing contrastive studying. It consists of two essential phases: Earlier than Coaching and Contrastive Studying for Coaching. This is an in depth clarification of every element:
Earlier than Coaching
1. Information Preprocessing:
- Dataset: The preliminary enter is a dataset containing code snippets.
- Normalized Code: The code snippets endure normalization to take away feedback and rename variables to an ordinary format. This helps in lowering the affect of variable naming on the educational course of and improves the generalizability of the mannequin.
- Code Transformation: The normalized code is then remodeled utilizing varied syntactic and semantic transformations to generate constructive samples. These transformations make sure that the semantic that means of the code stays unchanged, offering numerous and sturdy samples for contrastive studying.
2. Tokenization:
- Prepare Tokenizer: A tokenizer is skilled on the code dataset to transform code textual content into embeddings. This includes breaking down the code into smaller models, comparable to tokens, that may be processed by the mannequin.
- Embedding Dataset: The skilled tokenizer is used to transform your complete code dataset into embeddings, which function the enter for the contrastive studying part.
Contrastive Studying for Coaching
3. Coaching Course of:
- Prepare Pattern: A pattern from the coaching dataset is chosen because the question code illustration.
- Optimistic Pattern: The corresponding constructive pattern is the remodeled model of the question code, obtained throughout the knowledge preprocessing part.
- Unfavorable Samples in Batch: Unfavorable samples are all different code samples within the present mini-batch which might be totally different from the constructive pattern.
4. Encoder and Momentum Encoder:
- Transformer Encoder with Relative Place and MLP Projection Head: Each the question and constructive samples are fed right into a Transformer encoder. The encoder incorporates relative place encoding to seize the syntactic construction and relationships between tokens within the code. An MLP (Multi-Layer Perceptron) projection head is used to map the encoded representations to a lower-dimensional area the place the contrastive studying goal is utilized.
- Momentum Encoder: A momentum encoder can be used, which is up to date by a shifting common of the question encoder’s parameters. This helps preserve the consistency and variety of the representations, stopping the collapse of the contrastive loss. The detrimental samples are encoded utilizing this momentum encoder and enqueued for the contrastive studying course of.
5. Contrastive Studying Goal:
- Compute InfoNCE Loss (Similarity): The InfoNCE (Noise Contrastive Estimation) loss is computed to maximise the similarity between the question and constructive samples whereas minimizing the similarity between the question and detrimental samples. This goal ensures that the discovered embeddings are discriminative and sturdy, capturing the semantic similarity of the code snippets.
The complete framework leverages the strengths of contrastive studying to study significant and sturdy code embeddings from unlabeled knowledge. Using AST transformations and a momentum encoder additional enhances the standard and effectivity of the discovered representations, making TransformCode a strong software for varied software program engineering duties.
Key Options of TransformCode
- Flexibility and Adaptability: May be prolonged to numerous downstream duties requiring code illustration.
- Effectivity and Scalability: Doesn’t require a big mannequin or in depth coaching knowledge, supporting any programming language.
- Unsupervised and Supervised Studying: May be utilized to each studying eventualities by incorporating task-specific labels or aims.
- Adjustable Parameters: The variety of encoder parameters will be adjusted based mostly on obtainable computing sources.
TransformCode introduces A knowledge-augmentation approach referred to as AST transformation, making use of syntactic and semantic transformations to the unique code snippets. This generates numerous and sturdy samples for contrastive studying.
Purposes of Code Embeddings
Code embeddings have revolutionized varied elements of software program engineering by reworking code from a textual format to a numerical illustration usable by machine studying fashions. Listed here are some key functions:
Improved Code Search
Historically, code search relied on key phrase matching, which regularly led to irrelevant outcomes. Code embeddings allow semantic search, the place code snippets are ranked based mostly on their similarity in performance, even when they use totally different key phrases. This considerably improves the accuracy and effectivity of discovering related code inside giant codebases.
Smarter Code Completion
Code completion instruments recommend related code snippets based mostly on the present context. By leveraging code embeddings, these instruments can present extra correct and useful strategies by understanding the semantic that means of the code being written. This interprets to sooner and extra productive coding experiences.
Automated Code Correction and Bug Detection
Code embeddings can be utilized to determine patterns that always point out bugs or inefficiencies in code. By analyzing the similarity between code snippets and recognized bug patterns, these programs can routinely recommend fixes or spotlight areas which may require additional inspection.
Enhanced Code Summarization and Documentation Technology
Giant codebases typically lack correct documentation, making it tough for brand spanking new builders to grasp their workings. Code embeddings can create concise summaries that seize the essence of the code’s performance. This not solely improves code maintainability but additionally facilitates data switch inside improvement groups.
Improved Code Critiques
Code critiques are essential for sustaining code high quality. Code embeddings can help reviewers by highlighting potential points and suggesting enhancements. Moreover, they’ll facilitate comparisons between totally different code variations, making the evaluation course of extra environment friendly.
Cross-Lingual Code Processing
The world of software program improvement will not be restricted to a single programming language. Code embeddings maintain promise for facilitating cross-lingual code processing duties. By capturing the semantic relationships between code written in several languages, these strategies might allow duties like code search and evaluation throughout programming languages.




{kind=link}