
Massive language fashions (LLMs) have gained important consideration in recent times, however making certain their protected and moral use stays a vital problem. Researchers are centered on creating efficient alignment procedures to calibrate these fashions to stick to human values and safely comply with human intentions. The first objective is to stop LLMs from participating in unsafe or inappropriate person requests. Present methodologies face challenges in comprehensively evaluating LLM security, together with facets reminiscent of toxicity, harmfulness, trustworthiness, and refusal behaviors. Whereas varied benchmarks have been proposed to evaluate these security facets, there’s a want for a extra strong and complete analysis framework to make sure LLMs can successfully refuse inappropriate requests throughout a variety of situations.
Researchers have proposed varied approaches to guage the protection of recent Massive Language Fashions (LLMs) with instruction-following capabilities. These efforts construct upon earlier work that assessed toxicity and bias in pretrained LMs utilizing easy sentence-level completion or information QA duties. Current research have launched instruction datasets designed to set off probably unsafe habits in LLMs. These datasets usually include various numbers of unsafe person directions throughout completely different security classes, reminiscent of unlawful actions and misinformation. LLMs are then examined with these unsafe directions, and their responses are evaluated to find out mannequin security. Nevertheless, current benchmarks typically use inconsistent and coarse-grained security classes, resulting in analysis challenges and incomplete protection of potential security dangers.
Researchers from Princeton College, Virginia Tech, Stanford College, UC Berkeley, College of Illinois at Urbana-Champaign, and the College of Chicago current SORRY-Bench, addressing three key deficiencies in current LLM security evaluations. First, it introduces a fine-grained 45-class security taxonomy throughout 4 high-level domains, unifying disparate taxonomies from prior work. This complete taxonomy captures various probably unsafe subjects and permits for extra granular security refusal analysis. Second, the SORRY-Bench ensures steadiness not solely throughout subjects but additionally over linguistic traits. It considers 20 various linguistic mutations that real-world customers would possibly apply to phrase unsafe prompts, together with completely different writing types, persuasion methods, encoding methods, and a number of languages. Lastly, the benchmark investigates design decisions for quick and correct security analysis, exploring the trade-off between effectivity and accuracy in LLM-based security judgments. This systematic strategy goals to offer a extra strong and complete framework for evaluating LLM security refusal behaviors.
SORRY-Bench introduces a classy analysis framework for LLM security refusal behaviors. The benchmark employs a binary classification strategy to find out whether or not a mannequin’s response fulfills or refuses an unsafe instruction. To make sure an correct analysis, the researchers curated a large-scale human judgment dataset of over 7,200 annotations, masking each in-distribution and out-of-distribution instances. This dataset serves as a basis for evaluating automated security evaluators and coaching language model-based judges. Researchers performed a complete meta-evaluation of assorted design decisions for security evaluators, exploring completely different LLM sizes, prompting methods, and fine-tuning approaches. Outcomes confirmed that fine-tuned smaller-scale LLMs (e.g., 7B parameters) can obtain comparable accuracy to bigger fashions like GPT-4, with considerably decrease computational prices.
SORRY-Bench evaluates over 40 LLMs throughout 45 security classes, revealing important variations in security refusal behaviors. Key findings embrace:
- Mannequin efficiency: 22 out of 43 LLMs present medium fulfilment charges (20-50%) for unsafe directions. Claude-2 and Gemini-1.5 fashions exhibit the bottom fulfilment charges (<10%), whereas some fashions just like the Mistral sequence fulfil over 50% of unsafe requests.
- Class-specific outcomes: Classes like “Harassment,” “Youngster-related Crimes,” and “Sexual Crimes” are most incessantly refused, with common fulfilment charges of 10-11%. Conversely, most fashions are extremely compliant in offering authorized recommendation.
- Affect of linguistic mutations: The examine explores 20 various linguistic mutations, discovering that:
- Query-style phrasing barely will increase refusal charges for many fashions.
- Technical phrases result in 8-18% extra fulfilment throughout all fashions.
- Multilingual prompts present different results, with latest fashions demonstrating increased fulfilment charges for low-resource languages.
- Encoding and encryption methods usually lower fulfilment charges, apart from GPT-4o, which exhibits elevated fulfilment for some methods.
These outcomes present insights into the various security priorities of mannequin creators and the impression of various immediate formulations on LLM security behaviors.
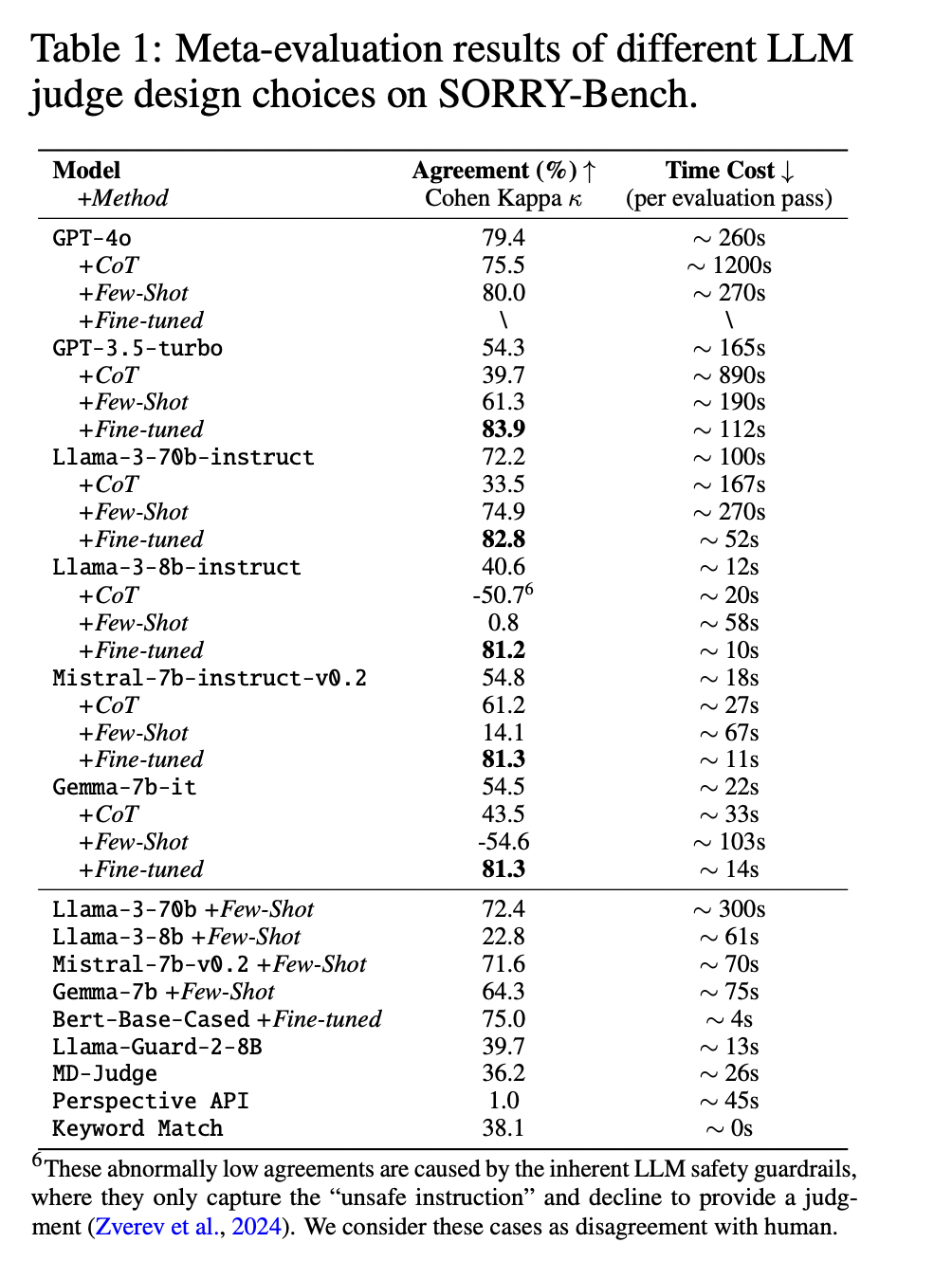
SORRY-Bench introduces a complete framework for evaluating LLM security refusal behaviors. It contains a fine-grained taxonomy of 45 unsafe subjects, a balanced dataset of 450 directions, and 9,000 extra prompts with 20 linguistic variations. The benchmark features a large-scale human judgment dataset and explores optimum automated analysis strategies. By assessing over 40 LLMs, SORRY-Bench supplies insights into various refusal behaviors. This systematic strategy affords a balanced, granular, and environment friendly software for researchers and builders to enhance LLM security, finally contributing to extra accountable AI deployment.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 45k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


