
Giant Language Fashions (LLMs) have gained important prominence within the AI business, revolutionizing varied functions comparable to chat, programming, and search. Nonetheless, the environment friendly serving of a number of LLMs has emerged as a vital problem for endpoint suppliers. The first problem lies within the substantial computational necessities of those fashions, with a single 175B LLM demanding eight A100 (80GB) GPUs for inference. Present methodologies, notably spatial partitioning, want to enhance in useful resource utilization. This method allocates separate GPU teams for every LLM, resulting in underutilization as a consequence of various mannequin recognition and request charges. Consequently, much less well-liked LLMs lead to idle GPUs, whereas well-liked ones expertise efficiency bottlenecks, highlighting the necessity for extra environment friendly serving methods.
Current makes an attempt to resolve LLM serving challenges have explored varied approaches. Deep studying serving techniques have targeted on temporal multiplexing and scheduling methods, however these are primarily designed for smaller fashions. LLM-specific techniques have superior by custom-made GPU kernels, parallelism strategies, and optimizations like reminiscence administration and offloading. Nonetheless, these strategies sometimes goal single LLM inference. GPU sharing strategies, together with temporal and spatial sharing, have been developed to enhance useful resource utilization, however they’re typically tailor-made for smaller DNN jobs. Whereas every method has made contributions, they collectively fall quick in addressing the distinctive necessities of effectively serving a number of LLMs, highlighting the necessity for a extra versatile and complete resolution.
Researchers from The Chinese language College of Hong Kong, Shanghai AI Laboratory, Huazhong College of Science and Know-how, Shanghai Jiao Tong College, Peking College, UC Berkeley, and the UC Sandiego current MuxServe, a versatile spatial-temporal multiplexing method for serving a number of LLMs, addressing GPU utilization challenges. It separates prefill and incremental decoding phases colocates jobs primarily based on LLM recognition, and employs an optimization framework to find out supreme useful resource allocation. The system makes use of a grasping placement algorithm, adaptive batch scheduling, and a unified useful resource supervisor to maximise effectivity. By partitioning GPU SMs with CUDA MPS, MuxServe achieves efficient spatial-temporal partitioning. This method leads to as much as 1.8× greater throughput than current techniques, marking a major development in environment friendly multi-LLM serving.
MuxServe introduces a versatile spatial-temporal multiplexing method for serving a number of LLMs effectively. The system formulates an optimization drawback to search out the perfect group of LLM models that maximize GPU utilization. It employs an enumeration-based grasping algorithm for LLM placement, prioritizing fashions with bigger computational necessities. To maximise intra-unit throughput, MuxServe makes use of an adaptive batch scheduling algorithm that balances prefill and decoding jobs whereas guaranteeing truthful useful resource sharing. A unified useful resource supervisor permits environment friendly multiplexing by dynamically allocating SM sources and implementing a head-wise cache for shared reminiscence utilization. This complete method permits MuxServe to successfully colocate LLMs with various recognition and useful resource wants, enhancing total system utilization.
MuxServe demonstrates superior efficiency in each artificial and real-world workloads. In artificial situations, it achieves as much as 1.8× greater throughput and processes 2.9× extra requests inside 99% SLO attainment in comparison with baseline techniques. The system’s effectivity varies with workload distribution, displaying explicit energy when LLM recognition is various. In actual workloads derived from ChatLMSYS traces, MuxServe outperforms spatial partitioning and temporal multiplexing by 1.38× and 1.46× in throughput, respectively. It constantly maintains greater SLO attainment throughout varied request charges. The outcomes spotlight MuxServe’s skill to effectively colocate LLMs with totally different recognition ranges, successfully multiplexing sources and enhancing total system utilization.
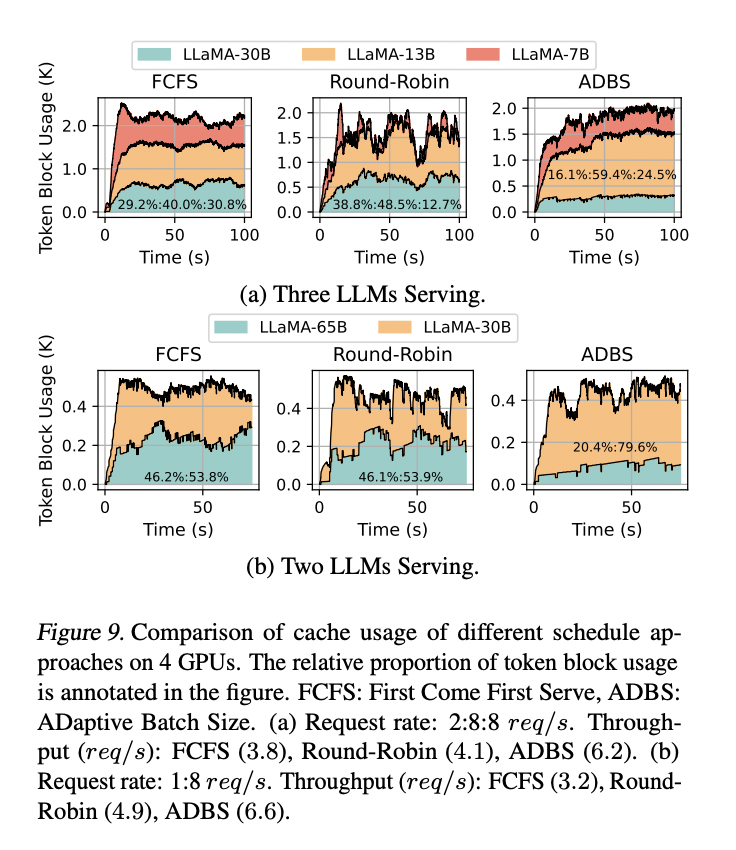
This research introduces MuxServe representing a major development within the discipline of LLM serving. By introducing versatile spatial-temporal multiplexing, the system successfully addresses the challenges of serving a number of LLMs concurrently. Its progressive method of colocating LLMs primarily based on their recognition and separating prefill and decoding jobs results in improved GPU utilization. This technique demonstrates substantial efficiency positive aspects over current techniques, reaching greater throughput and higher SLO attainment throughout varied workload situations. MuxServe’s skill to adapt to totally different LLM sizes and request patterns makes it a flexible resolution for the rising calls for of LLM deployment. Because the AI business continues to evolve, MuxServe supplies a promising framework for environment friendly and scalable LLM serving.
Try the Paper and Mission. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to affix our 45k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


