
Giant language fashions (LLMs) have made vital strides in pure language understanding and era. Nevertheless, they face a essential problem when dealing with lengthy contexts as a consequence of limitations in context window measurement and reminiscence utilization. This subject hinders their potential to course of and comprehend in depth textual content inputs successfully. Because the demand for LLMs to deal with more and more advanced and prolonged duties grows, addressing this limitation has grow to be a urgent concern for researchers and builders within the discipline of pure language processing.
Researchers have explored varied approaches to beat the challenges of long-context processing in LLMs. Mannequin-level strategies, equivalent to positional interpolation and transformer variants with modified consideration mechanisms, have proven promise however include vital drawbacks. These embody elevated coaching prices, neglect of detailed data, and lack of earlier context. Alternatively, retrieval-based strategies like Retrieval Augmented Technology (RAG) have been developed to make the most of exterior databases for data extraction. Nevertheless, RAG struggles with advanced questions as a consequence of limitations in decision-making mechanisms. Agent-based approaches have emerged as a possible resolution, using LLMs’ planning and reflection skills to deal with advanced issues and retrieve unstructured data. Regardless of these developments, current strategies nonetheless face difficulties in dealing with multi-hop questions and totally exploiting the capabilities of LLMs as brokers.
Researchers from Alibaba Group, The Chinese language College of Hong Kong, Shanghai AI Laboratory, and the College of Manchester launched GraphReader, a strong graph-based agent system to deal with the challenges of long-context processing in LLMs. This modern strategy segments prolonged texts into discrete chunks, extracting and compressing important data into key components and atomic details. These parts are then used to assemble a graph construction that successfully captures long-range dependencies and multi-hop relationships throughout the textual content. The agent autonomously explores this graph utilizing predefined capabilities and a step-by-step rational plan, progressively accessing data from coarse components to detailed unique textual content chunks. This course of includes taking notes and reflecting till adequate data is gathered to generate a solution. GraphReader’s design goals to determine a scalable long-context functionality based mostly on a 4k context window, probably rivaling or surpassing the efficiency of GPT-4 with a 128k context window throughout varied context lengths.
GraphReader is constructed on a graph construction, the place every node incorporates a key factor and a set of atomic details. This construction allows the seize of worldwide data from lengthy enter paperwork inside a restricted context window. The system operates in three essential phases: graph building, graph exploration, and reply reasoning. Throughout graph building, the doc is break up into chunks, summarized into atomic details, and key components are extracted. Nodes are created from these parts and linked based mostly on shared key components. Within the graph exploration section, the agent initializes by defining a rational plan and deciding on preliminary nodes. It then explores the graph by analyzing atomic details, studying related chunks, and investigating neighbouring nodes. The agent maintains a pocket book to document supporting details all through the exploration. Lastly, within the reply reasoning section, the system compiles notes from a number of brokers, analyzes them utilizing Chain-of-Thought reasoning, and generates a closing reply to the given query.
The analysis of GraphReader and different strategies on a number of long-context benchmarks reveals a number of key findings. GraphReader persistently outperforms different approaches throughout varied duties and context lengths. On multi-hop QA duties, GraphReader achieves superior efficiency in comparison with RAG strategies, long-context LLMs, and different agent-based approaches. As an illustration, on the HotpotQA dataset, GraphReader achieves 55.0% EM and 70.0% F1 scores, surpassing GPT-4-128k and ReadAgent. GraphReader’s effectiveness extends to extraordinarily lengthy contexts, as demonstrated within the LV-Eval benchmark. It maintains sturdy efficiency throughout textual content lengths from 16k to 256k tokens, displaying a relative efficiency achieve of 75.00% over GPT-4-128k at 128k context size. This superior efficiency is attributed to GraphReader’s graph-based exploration technique, which effectively captures relationships between key data and facilitates efficient multi-hop reasoning in lengthy contexts.
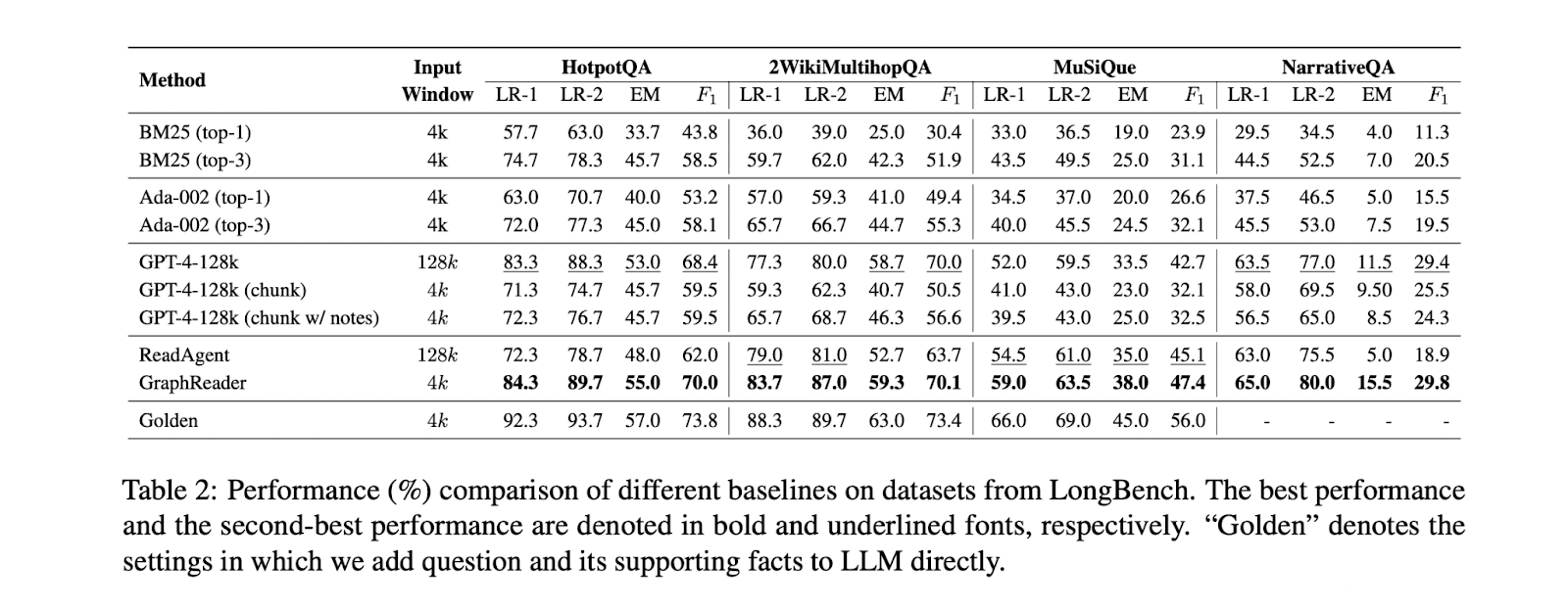
GraphReader represents a big development in addressing long-context challenges in massive language fashions. By organizing in depth texts into graph constructions and using an autonomous agent for exploration, it successfully captures long-range dependencies inside a compact 4k context window. Its superior efficiency, outperforming GPT-4 with a 128k enter size throughout varied question-answering duties, demonstrates its efficacy in dealing with advanced reasoning situations. This breakthrough opens new potentialities for making use of LLMs to duties involving prolonged paperwork and complex multi-step reasoning, probably revolutionizing fields like doc evaluation and analysis help. GraphReader units a brand new benchmark for long-context processing, paving the way in which for extra superior language fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 45k+ ML SubReddit
🚀 Create, edit, and increase tabular knowledge with the primary compound AI system, Gretel Navigator, now typically accessible! [Advertisement]
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


