
Lengthy-context language fashions (LCLMs) have emerged as a promising know-how with the potential to revolutionize synthetic intelligence. These fashions purpose to sort out advanced duties and purposes whereas eliminating the necessity for intricate pipelines that have been beforehand essential resulting from context size limitations. Nonetheless, the event and analysis of LCLMs face important challenges. Present analysis strategies depend on artificial duties or fixed-length datasets that fail to adequately assess the true capabilities of those fashions in real-world eventualities. The shortage of rigorous benchmarks for actually long-context duties hinders the flexibility to stress-test LCLMs on paradigm-shifting purposes. Addressing these limitations is essential for realizing the total potential of LCLMs and their affect on AI improvement.
Researchers have made a number of makes an attempt to guage LCLMs, however every method has limitations. Whereas scalable, artificial duties like “Needle-in-A-Haystack” retrieval and multi-hop QA fail to seize the complexities of real-world eventualities. Different benchmarks utilizing present NLP datasets for excessive summarization and multi-document QA lack dynamic scaling capabilities, making them unsuitable for very lengthy contexts. Instruction-following evaluations like LongAlpaca and LongBench-Chat supply restricted job variety and context lengths. Ada-LEval proposes a length-adaptable benchmark however depends on considerably artificial duties. Research on long-context QA utilizing retrieved paperwork have proven promising outcomes however are restricted to contexts underneath 10,000 tokens. These present strategies fall wanting comprehensively evaluating LCLMs on various, real-world duties with actually lengthy contexts, highlighting the necessity for extra sturdy analysis frameworks.
DeepMind Researchers introduce the Lengthy-Context Frontiers (LOFT) to beat the constraints of present analysis strategies for LCLMs. LOFT contains six duties throughout 35 datasets, encompassing textual content, visible, and audio modalities. This complete benchmark is designed to push LCLMs to their limits and assess their real-world affect. In contrast to earlier evaluations, LOFT permits for the automated creation of accelerating context lengths, at present extending to at least one million tokens with the potential for additional growth. The benchmark focuses on 4 key areas the place LCLMs have disruptive potential: retrieval throughout a number of modalities, retrieval-augmented era (RAG), SQL-free database querying, and many-shot in-context studying. By concentrating on these areas, LOFT goals to offer a rigorous and scalable analysis framework that may hold tempo with the evolving capabilities of LCLMs.
The LOFT benchmark encompasses a various vary of real-world purposes to guage LCLMs comprehensively. It options six fundamental duties: retrieval, RAG, SQL-like reasoning, and many-shot in-context studying (ICL), spanning 35 datasets throughout textual content, visible, and audio modalities. The benchmark is designed with three context size limits: 32k, 128k, and 1M tokens, with the potential to scale additional. For retrieval and RAG duties, LOFT creates shared corpora containing gold passages and random samples, guaranteeing smaller corpora are subsets of bigger ones. Many-shot ICL duties adapt datasets from Large-Bench Laborious and LongICLBench, whereas SQL duties use Spider and SparC datasets with related databases. This construction permits for rigorous analysis of LCLMs’ efficiency throughout numerous context lengths and job varieties.
The LOFT benchmark evaluates Gemini 1.5 Professional, GPT-4, and Claude 3 Opus throughout numerous duties and context lengths. Gemini 1.5 Professional performs effectively in textual content retrieval, visible retrieval, and audio retrieval, usually matching or exceeding specialised fashions. It excels in multi-hop RAG duties however struggles with multi-target datasets at bigger scales. SQL-like reasoning duties present potential however require enchancment. Many-shot ICL outcomes fluctuate, with Gemini 1.5 Professional and Claude 3 Opus performing strongly in numerous areas. The benchmark highlights LCLMs’ rising capabilities throughout various duties and modalities, whereas additionally figuring out areas for enchancment, significantly in scaling to bigger contexts and sophisticated reasoning.
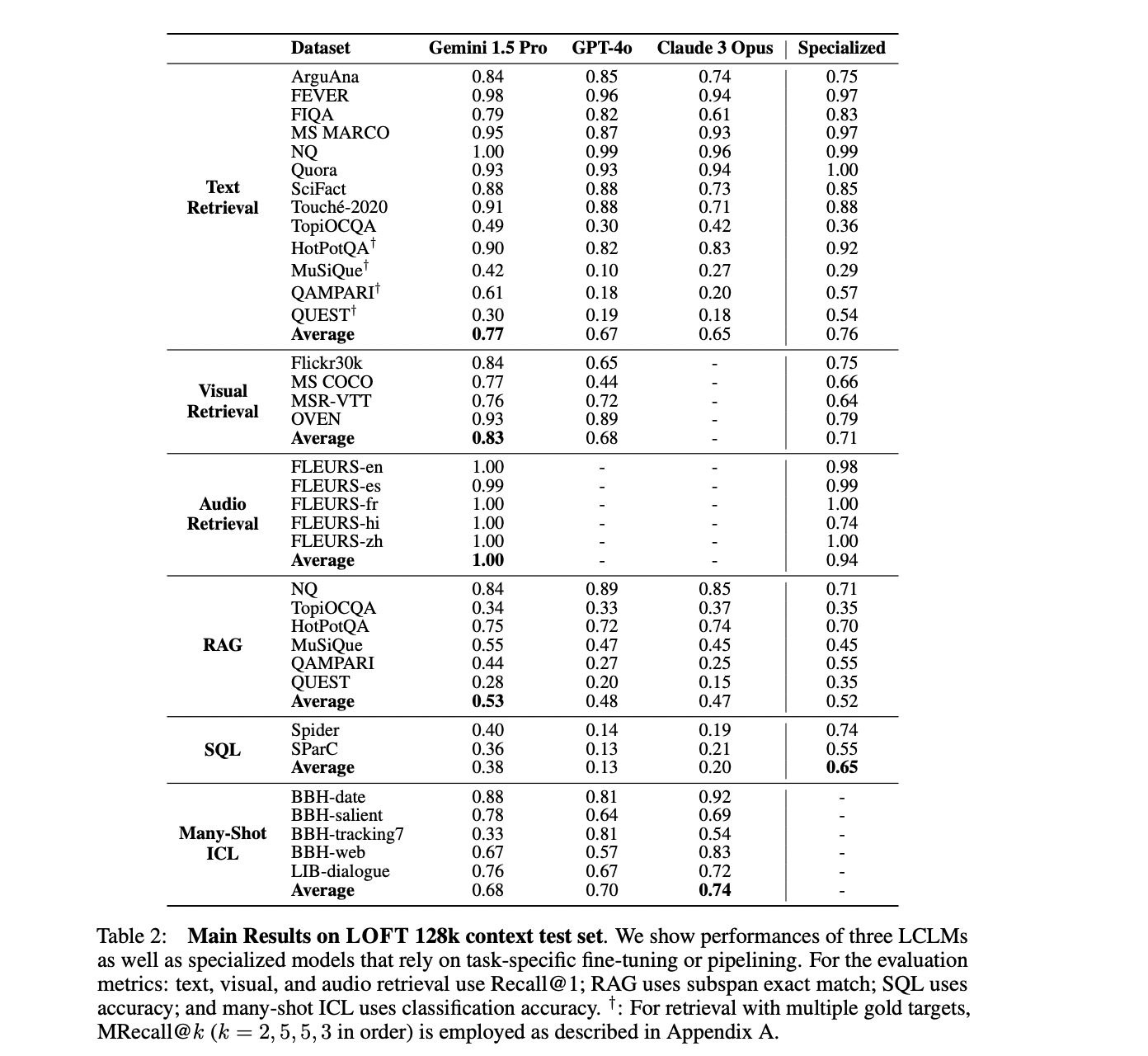
On this examine LOFT benchmark has been launched to evaluate the evolving capabilities of Massive Context Language Fashions (LCLMs) as they scale to deal with more and more lengthy contexts. LOFT contains duties designed to guage LCLMs on potential paradigm-shifting purposes: retrieval, retrieval-augmented era, SQL-like reasoning, and in-context studying. With dynamic scaling as much as 1 million tokens and the potential to increase to 1 billion, LOFT ensures ongoing relevance as LCLMs advance. Preliminary outcomes present LCLMs demonstrating aggressive retrieval capabilities in comparison with specialised programs, regardless of missing particular coaching. Nonetheless, the benchmark additionally reveals important room for enchancment in long-context reasoning, significantly as fashions entry even longer context home windows.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 45k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


