
Textual content embeddings (TEs) are low-dimensional vector representations of texts of various sizes, that are vital for a lot of pure language processing (NLP) duties. In contrast to high-dimensional and sparse representations like TF-IDF, dense TEs are able to fixing the lexical mismatch downside and bettering the effectivity of textual content retrieval and matching. Pre-trained language fashions, like BERT and GPT, have proven nice success in varied NLP duties. Nonetheless, getting a high-quality sentence embedding from these fashions is difficult because of the anisotropic embedding areas created by the masked language modeling goal.
TEs are normally examined on a small variety of datasets from one particular job, which doesn’t present how properly they could work for different duties. It’s not clear that the state-of-the-art embeddings for semantic textual similarity (STS) can remedy duties like clustering or reranking, making it difficult to trace progress. To handle this downside, the Huge Textual content Embedding Benchmark (MTEB) was launched, which covers 8 embedding duties, 58 datasets, and 112 languages. By testing 33 fashions on MTEB, probably the most thorough benchmark has been developed for TEs to this point the place no single TE technique works greatest for all duties. This implies a common TE technique that performs at a state-of-the-art stage throughout all duties remains to be not found.
Alibaba researchers have simply launched a brand new embedding mannequin referred to as gte-Qwen1.5-7B-instruct, following their earlier gte-Qwen1.5-7B-instruct mannequin. The primary change is that the brand new mannequin relies on Qwen2-7B as a substitute of Qwen1.5-7B, highlighting the enhancements of Qwen2-7B. The efficiency has a drastic enhance with an total rating improved from 67.34 to 70.24, and nDCG@10 for Retrieval on the MTEB leaderboard went from 57.91 to 60.25. This mannequin comprises 7B parameters, which may be very massive for embedding fashions, and it helps a most sequence size of 32k (max enter tokens). Furthermore, it’s built-in with Sentence Transformers, making it suitable with instruments corresponding to LangChain, LlamaIndex, Haystack, and many others.
The gte-Qwen2-7B-instruct is the newest mannequin within the Common Textual content Embedding (gte) mannequin household. As of June 21, 2024, it ranks 2nd in each English and Chinese language evaluations on the Huge Textual content Embedding Benchmark (MTEB). The gte-Qwen2-7B-instruct mannequin is educated primarily based on the Qwen2-7B LLM mannequin, which is current within the Qwen2 collection fashions launched by the Qwen staff not too long ago. This new mannequin makes use of the identical coaching knowledge and methods as the sooner gte-Qwen1.5-7B-instruct mannequin however with the up to date Qwen2-7B base mannequin. Given the enhancements within the Qwen2 collection fashions in comparison with the Qwen1.5 collection, constant efficiency enhancements are anticipated within the embedding fashions.
The gte-Qwen2-7B-instruct mannequin makes use of a number of vital options:
- Incorporating bidirectional consideration mechanisms enhances its skill for contextual understanding.
- Instruction Tuning is a crucial method that’s utilized solely on the question aspect for higher effectivity.
- Complete Coaching is a course of wherein the mannequin is educated on a big, multilingual textual content assortment from varied domains and conditions. It makes use of each weakly supervised and supervised knowledge to make it helpful for a lot of languages and varied duties.
Furthermore, the gte collection fashions have launched two forms of fashions, Encoder-only fashions that are primarily based on the BERT structure, and Decode-only fashions that are primarily based on the LLM structure.
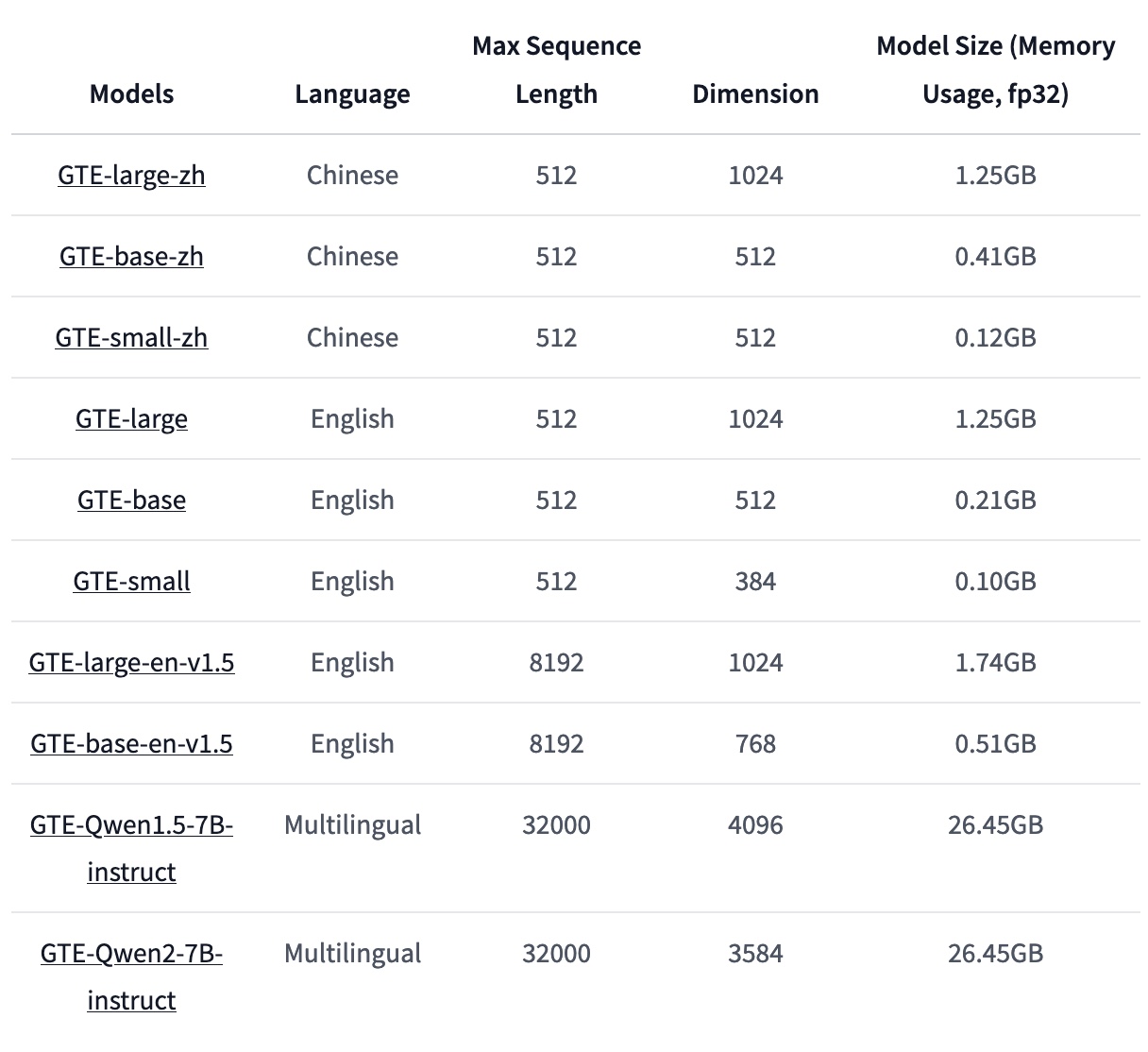
In conclusion, Alibaba researchers have launched the gte-Qwen2-7B-instruct mannequin, succeeding the earlier gte-Qwen1.5-7B-instruct mannequin. The brand new mannequin, primarily based on Qwen2-7B, exhibits improved efficiency with a better total rating and higher retrieval metrics. It helps as much as 32k enter tokens and integrates with Sentence Transformers, making it usable with varied instruments corresponding to LangChain, LlamaIndex, Haystack, and many others. Additionally, the mannequin ranks first in each English and Chinese language on the MTEB as of June 16, 2024. It makes use of bidirectional consideration for higher context understanding and instruction tuning for effectivity. Lastly, the gte collection consists of each encoder-only (BERT-based) and decode-only (LLM-based) fashions.

Sajjad Ansari is a ultimate 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.


