
The area of synthetic intelligence has been considerably formed by the emergence of enormous language fashions (LLMs), displaying huge potential throughout numerous fields. Nevertheless, enabling LLMs to successfully make the most of laptop science data and serve humanity extra effectively stays a key problem. Regardless of current research overlaying a number of fields, together with laptop science, there’s a scarcity of complete analysis particularly targeted on LLMs’ efficiency in laptop science. This hole overlooks the significance of completely assessing the sector and guiding LLM growth to advance their capabilities in laptop science.
Latest analysis has explored LLMs’ potential in numerous industries and scientific fields. Nevertheless, research on LLMs in laptop science fall into two foremost classes: broad analysis benchmarks the place laptop science constitutes solely a small fraction, and explorations of particular LLM purposes inside laptop science. Neither method offers a complete analysis of LLMs’ foundational data and reasoning skills within the area. Whereas particular person capabilities like arithmetic, coding, and logical reasoning have been well-studied, analysis on their built-in utility and interrelationships stays sparse.
Researchers from Beijing College of Posts and Telecommunications suggest CS-Bench, the primary benchmark devoted to evaluating LLMs’ efficiency in laptop science. CS-Bench options high-quality, various process kinds, various capacities, and bilingual analysis. It includes roughly 5,000 fastidiously curated check objects spanning 26 sections throughout 4 key laptop science domains. The benchmark consists of multiple-choice, assertion, fill-in-the-blank, and open-ended questions to raised simulate real-world eventualities and assess LLMs’ robustness to totally different process codecs. CS-Bench evaluates each knowledge-type and reasoning-type questions, supporting bilingual analysis in Chinese language and English.
CS-Bench covers 4 key domains: Knowledge Construction and Algorithm (DSA), Pc Group (CO), Pc Community(CN), and Working System(OS). It consists of 26 fine-grained subfields and various process kinds to counterpoint evaluation dimensions and simulate real-world eventualities. The info for CS-Bench comes from numerous sources, together with publicly accessible on-line channels, tailored weblog articles, and licensed educating supplies. The info processing includes a workforce of laptop science graduates who parse questions and solutions, label query varieties, and guarantee high quality by means of thorough handbook checks. The benchmark helps bilingual evaluation with a complete of 4,838 samples throughout numerous process codecs.
Analysis outcomes present that total scores of fashions vary from 39.86% to 72.29%. GPT-4 and GPT-4o signify the best commonplace on CS-Bench, being the one fashions exceeding 70% proficiency. Open-source fashions like Qwen1.5-110B and Llama3-70B have surpassed beforehand sturdy closed-source fashions. Newer fashions show important enhancements in comparison with earlier variations. All fashions carry out worse on reasoning in comparison with data scores, indicating that reasoning poses a larger problem. LLMs typically carry out finest in Knowledge Construction and Algorithm and worst in Working Methods. Stronger fashions show a greater skill to make use of data for reasoning and present extra robustness throughout totally different process codecs.
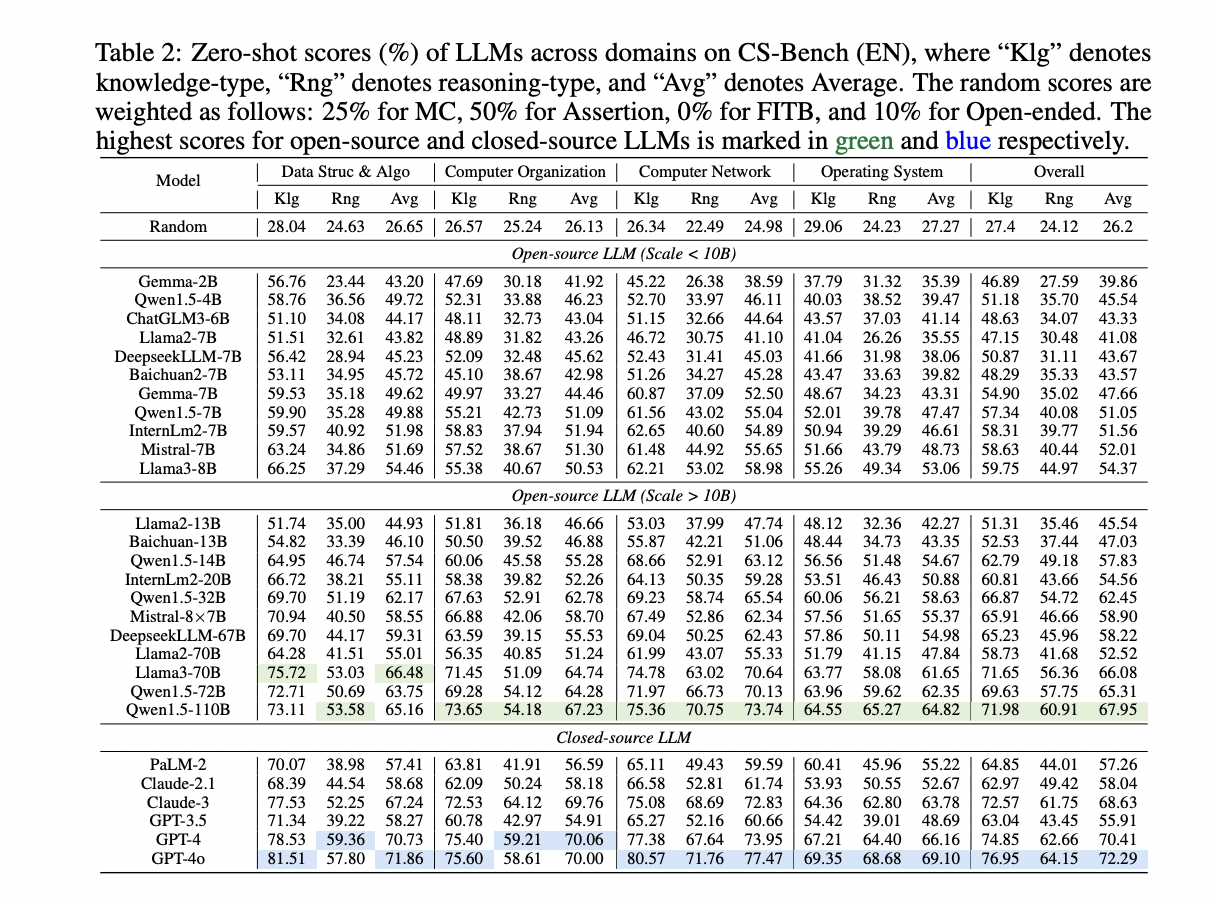
This examine introduces CS-Bench to offer worthwhile insights into LLMs’ efficiency in laptop science. Even top-performing fashions like GPT-4o have important room for enchancment. The benchmark highlights the shut interconnections between laptop science, arithmetic, and coding skills in LLMs. These findings provide instructions for enhancing LLMs within the area and supply worthwhile insights into their cross-abilities and purposes, paving the way in which for future developments in AI and laptop science.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Neglect to hitch our 45k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


