
Knowledge curation is important for growing high-quality coaching datasets for language fashions. This course of contains strategies comparable to deduplication, filtering, and information mixing, which improve the effectivity and accuracy of fashions. The objective is to create datasets that enhance the efficiency of fashions throughout varied duties, from pure language understanding to complicated reasoning.
A big problem in coaching language fashions is the necessity for standardized benchmarks for information curation methods. This makes it troublesome to discern whether or not enhancements in mannequin efficiency are as a result of higher information curation or different components, comparable to mannequin structure or hyperparameters. This ambiguity hinders the optimization of coaching datasets successfully, making it difficult for researchers to develop extra correct and environment friendly fashions.
Present strategies for information curation embody deduplication, filtering, and utilizing model-based approaches to assemble coaching units. These strategies are utilized to giant datasets to scale back redundancy and improve high quality. Nonetheless, the efficiency of those methods varies considerably, and there must be a consensus on the simplest method for curating coaching information for language fashions. The necessity for clearer, standardized benchmarks additional complicates this course of, making it troublesome to match the effectiveness of various information curation strategies.
A crew of researchers from varied reputed institutes together with the College of Washington, Apple, and the Toyota Analysis Institute have launched a novel information curation workflow referred to as DataComp for Language Fashions (DCLM). This methodology goals to create high-quality coaching datasets and set up a benchmark for evaluating dataset efficiency. This interdisciplinary method combines experience from varied fields to sort out the complicated situation of knowledge curation for language fashions.
The DCLM workflow includes a number of vital steps. Initially, textual content is extracted from uncooked HTML utilizing Resiliparse, a extremely environment friendly textual content extraction software. Deduplication is carried out utilizing a Bloom filter to take away redundant information, which helps enhance information range and reduces memorization in fashions. That is adopted by model-based filtering, which employs a fastText classifier skilled on high-quality information from sources like OpenWebText2 and ELI5. These steps are essential for making a high-quality coaching dataset often known as DCLM-BASELINE. The meticulous course of ensures that solely probably the most related and high-quality information is included within the coaching set.
The DCLM-BASELINE dataset demonstrated important enhancements in mannequin efficiency. When used to coach a 7B parameter language mannequin with 2.6 trillion coaching tokens, the ensuing mannequin achieved a 64% 5-shot accuracy on MMLU. This represents a considerable enhancement over earlier fashions and highlights the effectiveness of the DCLM methodology in producing high-quality coaching datasets. The analysis crew in contrast their outcomes with state-of-the-art fashions, comparable to GPT-4 and Llama 3, demonstrating that the DCLM-BASELINE mannequin performs competitively, even with lowered computational assets.
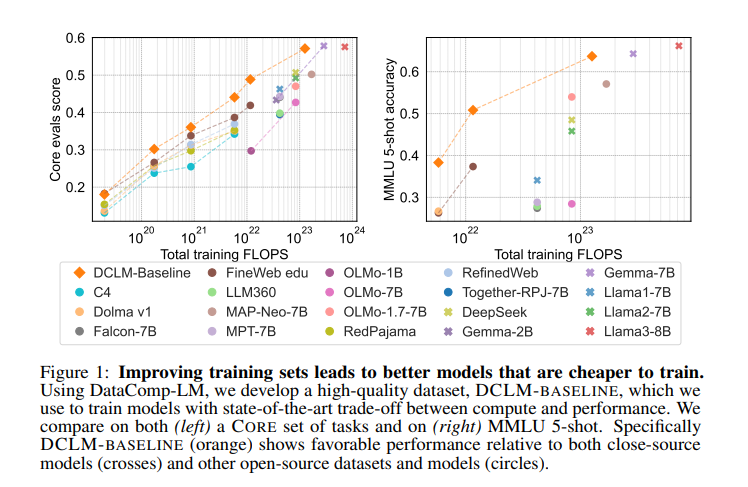
The proposed DCLM workflow units a brand new benchmark for information curation in language fashions. It offers a complete framework for evaluating and bettering coaching datasets, which is important for advancing the sphere of language modeling. The analysis crew encourages additional exploration of knowledge curation methods to construct more practical and environment friendly language fashions. They spotlight the potential for future analysis to develop on their findings, exploring completely different information sources, filtering strategies, and mannequin architectures to proceed bettering the standard of coaching datasets.
In conclusion, the DCLM workflow, a product of a collaborative effort by establishments just like the College of Washington, Apple, and the Toyota Analysis Institute, affords a sturdy resolution to enhance dataset high quality and mannequin efficiency. This method units a brand new benchmark for future analysis in information curation and language mannequin growth. The collaborative nature of this analysis underscores the significance of interdisciplinary approaches in addressing complicated analysis issues. This progressive workflow not solely advances the present state of language modeling but in addition paves the way in which for future enhancements within the area.
Take a look at the Paper and Undertaking. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 44k+ ML SubReddit
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


