
Giant language fashions (LLMs) have made vital strides in dealing with a number of modalities and duties, however they nonetheless want to enhance their skill to course of numerous inputs and carry out a variety of duties successfully. The first problem lies in growing a single neural community able to dealing with a broad spectrum of duties and modalities whereas sustaining excessive efficiency throughout all domains. Present fashions, reminiscent of 4M and UnifiedIO, present promise however are constrained by the restricted variety of modalities and duties they’re skilled on. This limitation hinders their sensible utility in situations requiring actually versatile and adaptable AI programs.
Latest makes an attempt to unravel multitask studying challenges in imaginative and prescient have advanced from combining dense imaginative and prescient duties to integrating quite a few duties into unified multimodal fashions. Strategies like Gato, OFA, Pix2Seq, UnifiedIO, and 4M remodel numerous modalities into discrete tokens and practice Transformers utilizing sequence or masked modeling goals. Some approaches allow a variety of duties by way of co-training on disjoint datasets, whereas others, like 4M, use pseudo labeling for any-to-any modality prediction on aligned datasets. Masked modeling has confirmed efficient in studying cross-modal representations, essential for multimodal studying, and permits generative purposes when mixed with tokenization.
Researchers from Apple and the Swiss Federal Institute of Expertise Lausanne (EPFL) construct their technique upon the multimodal masking pre-training scheme, considerably increasing its capabilities by coaching on a various set of modalities. The method incorporates over 20 modalities, together with SAM segments, 3D human poses, Canny edges, colour palettes, and numerous metadata and embeddings. Through the use of modality-specific discrete tokenizers, the tactic encodes numerous inputs right into a unified format, enabling the coaching of a single mannequin on a number of modalities with out efficiency degradation. This unified method expands current capabilities throughout a number of key axes, together with elevated modality assist, improved variety in information sorts, efficient tokenization strategies, and scaled mannequin dimension. The ensuing mannequin demonstrates new prospects for multimodal interplay, reminiscent of cross-modal retrieval and extremely steerable era throughout all coaching modalities.
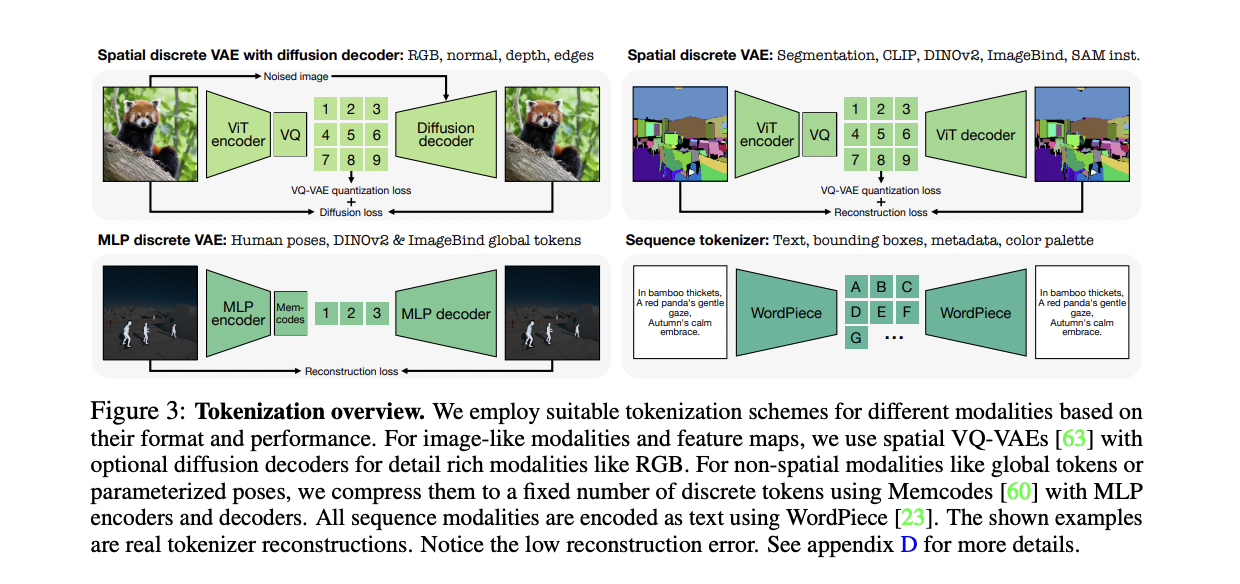
This technique adopts the 4M pre-training scheme, increasing it to deal with a various set of modalities. It transforms all modalities into sequences of discrete tokens utilizing modality-specific tokenizers. The coaching goal includes predicting one subset of tokens from one other, utilizing random picks from all modalities as inputs and targets. It makes use of pseudo-labeling to create a big pre-training dataset with a number of aligned modalities. The tactic incorporates a variety of modalities, together with RGB, geometric, semantic, edges, function maps, metadata, and textual content. Tokenization performs a vital function in unifying the illustration house throughout these numerous modalities. This unification permits coaching with a single pre-training goal, improves coaching stability, permits full parameter sharing, and eliminates the necessity for task-specific parts. Three principal forms of tokenizers are employed: ViT-based tokenizers for image-like modalities, MLP tokenizers for human poses and world embeddings, and a WordPiece tokenizer for textual content and different structured information. This complete tokenization method permits the mannequin to deal with a wide selection of modalities effectively, lowering computational complexity and enabling generative duties throughout a number of domains.
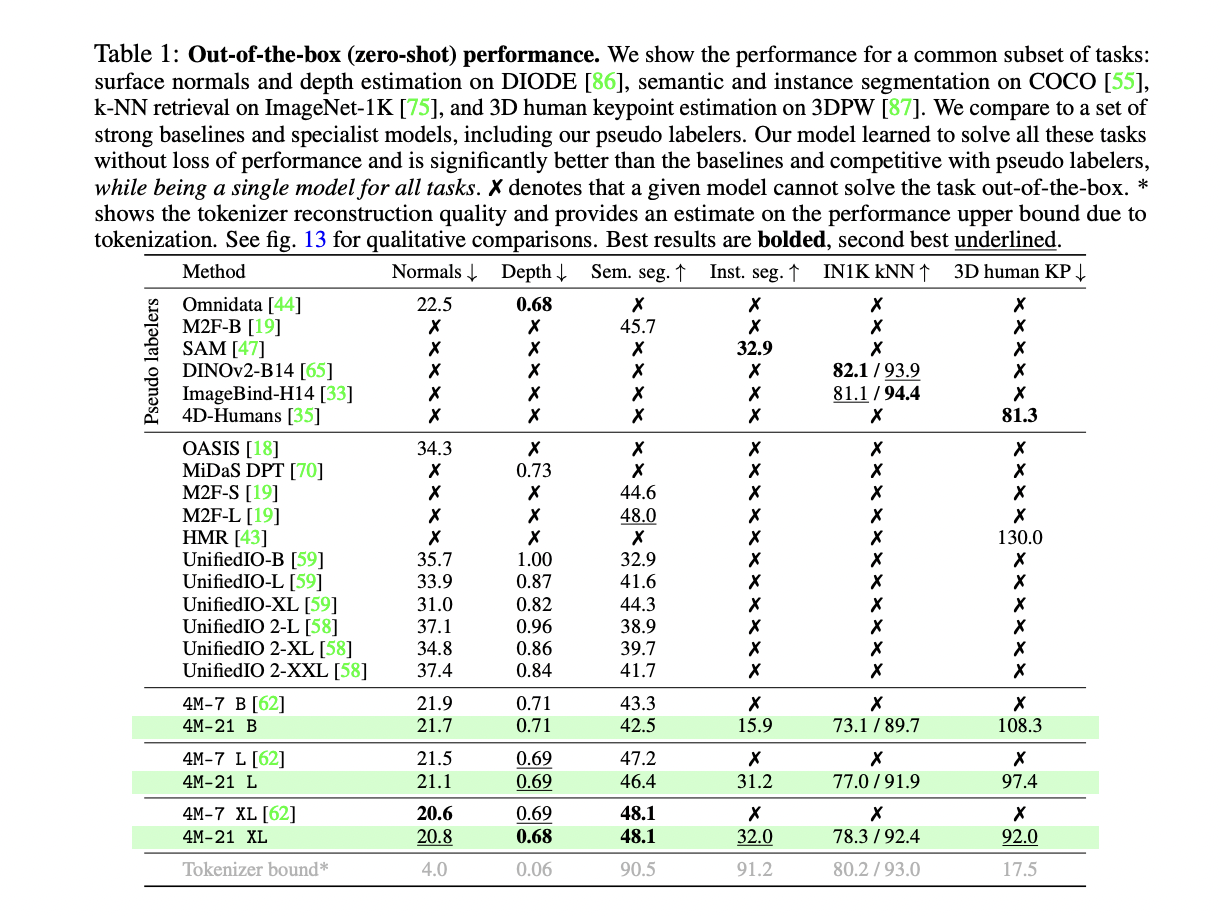
The 4M-21 mannequin demonstrates a variety of capabilities, together with steerable multimodal era, multimodal retrieval, and powerful out-of-the-box efficiency throughout numerous imaginative and prescient duties. It will possibly predict any coaching modality by iteratively decoding tokens, enabling fine-grained and multimodal era with improved textual content understanding. The mannequin performs multimodal retrievals by predicting world embeddings from any enter modality, permitting for versatile retrieval capabilities. In out-of-the-box evaluations, 4M-21 achieves aggressive efficiency on duties reminiscent of floor regular estimation, depth estimation, semantic segmentation, occasion segmentation, 3D human pose estimation, and picture retrieval. It typically matches or outperforms specialist fashions and pseudo-labelers whereas being a single mannequin for all duties. The 4M-21 XL variant, particularly, demonstrates robust efficiency throughout a number of modalities with out sacrificing functionality in any single area.

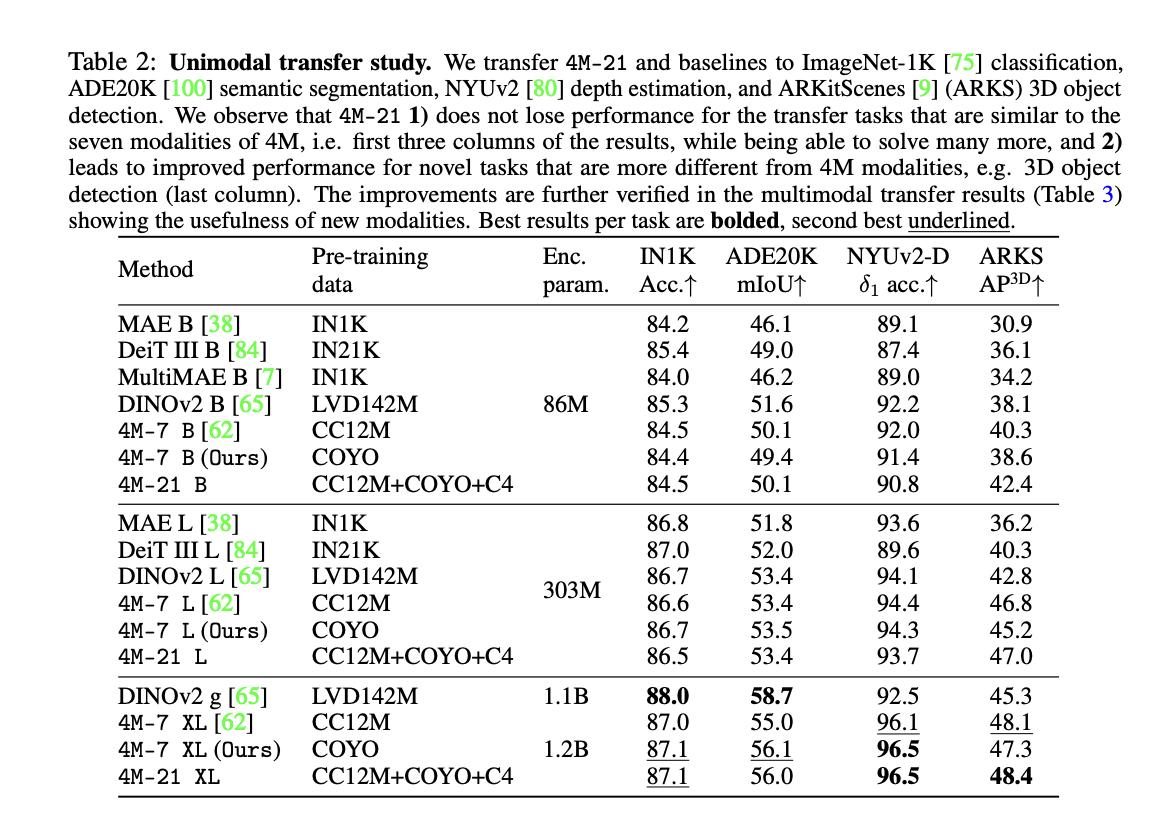
Researchers look at the scaling traits of pre-training any-to-any fashions on a big set of modalities, evaluating three mannequin sizes: B, L, and XL. Evaluating each unimodal (RGB) and multimodal (RGB + Depth) switch studying situations. In unimodal transfers, 4M-21 maintains efficiency on duties just like the unique seven modalities whereas exhibiting improved outcomes on advanced duties like 3D object detection. The mannequin demonstrates higher efficiency with elevated dimension, indicating promising scaling traits. For multimodal transfers, 4M-21 successfully makes use of non-compulsory depth inputs, considerably outperforming baselines. The examine reveals that coaching on a broader set of modalities doesn’t compromise efficiency on acquainted duties and may improve capabilities on new ones, particularly as mannequin dimension will increase.
This analysis demonstrates the profitable coaching of an any-to-any mannequin on a various set of 21 modalities and duties. This achievement is made doable by using modality-specific tokenizers to map all modalities to discrete units of tokens, coupled with a multimodal masked coaching goal. The mannequin scales to 3 billion parameters throughout a number of datasets with out compromising efficiency in comparison with extra specialised fashions. The ensuing unified mannequin displays robust out-of-the-box capabilities and opens new avenues for multimodal interplay, era, and retrieval. Nonetheless, the examine acknowledges sure limitations and areas for future work. These embrace the necessity to additional discover switch and emergent capabilities, which stay largely untapped in comparison with language fashions.
Take a look at the Paper, Mission, and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our 44k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


