Deploying massive language fashions (LLMs) on resource-constrained units presents important challenges as a consequence of their intensive parameters and reliance on dense multiplication operations. This leads to excessive reminiscence calls for and latency bottlenecks, hindering their sensible software in real-world situations. As an illustration, fashions like GPT-3 require immense computational sources, making them unsuitable for a lot of edge and cloud environments. Overcoming these challenges is essential for the development of AI, as it could allow the environment friendly deployment of highly effective LLMs, thereby broadening their applicability and influence.
Present strategies to boost the effectivity of LLMs embrace pruning, quantization, and a focus optimization. Pruning strategies cut back mannequin dimension by eradicating much less important parameters, however this usually results in accuracy loss. Quantization, notably post-training quantization (PTQ), reduces the bit-width of weights and activations to decrease reminiscence and computation calls for. Nonetheless, current PTQ strategies both require important retraining or result in accuracy degradation as a consequence of quantization errors. Moreover, these strategies nonetheless rely closely on pricey multiplication operations, limiting their effectiveness in decreasing latency and vitality consumption.
Researchers from Google, Intel, and Georgia Institute of Know-how suggest ShiftAddLLM, a way that accelerates pre-trained LLMs by way of post-training shift-and-add reparameterization. This strategy replaces conventional multiplications with hardware-friendly shift and add operations. Particularly, it quantizes weight matrices into binary matrices with group-wise scaling components. These multiplications are then reparameterized into shifts between activations and scaling components, and queries and provides based mostly on the binary matrices. This technique addresses the constraints of current quantization strategies by minimizing each weight and activation reparameterization errors by way of a multi-objective optimization framework. This progressive strategy considerably reduces reminiscence utilization and latency whereas sustaining or bettering mannequin accuracy.
ShiftAddLLM employs a multi-objective optimization technique to align weight and output activation targets, minimizing general reparameterization errors. The researchers launched an automatic bit allocation technique, optimizing the bit-widths for weights in every layer based mostly on their sensitivity to reparameterization. This technique ensures that extra delicate layers obtain higher-bit representations, thus avoiding accuracy loss whereas maximizing effectivity. The proposed technique is validated throughout 5 LLM households and eight duties, displaying common perplexity enhancements of 5.6 and 22.7 factors at comparable or decrease latency in comparison with the very best current quantized LLMs. Moreover, ShiftAddLLM achieves over 80% reductions in reminiscence and vitality consumption.
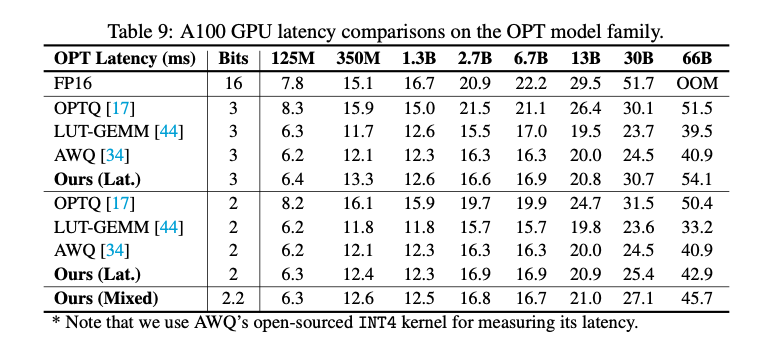
The experimental outcomes exhibit the effectiveness of ShiftAddLLM. Vital enhancements in perplexity scores throughout varied fashions and duties had been reported. For instance, ShiftAddLLM achieves perplexity reductions of 5.63/38.47/5136.13 in comparison with OPTQ, LUT-GEMM, and AWQ at 3 bits, respectively. In 2-bit settings, the place most baselines fail, ShiftAddLLM maintains low perplexity and achieves a mean discount of twenty-two.74 perplexity factors over essentially the most aggressive baseline, QuIP. The tactic additionally reveals higher accuracy-latency trade-offs, with as much as 103830.45 perplexity discount and as much as 60.1% latency reductions. The beneath key end result desk compares perplexity scores and latencies of varied strategies, highlighting ShiftAddLLM’s superior efficiency in each metrics.
In conclusion, the researchers current ShiftAddLLM, a big development within the environment friendly deployment of LLMs. The tactic reparameterizes weight matrices into shift-and-add operations, drastically decreasing computational prices whereas sustaining excessive accuracy. This innovation is achieved by way of a multi-objective optimization technique and an automatic bit allocation strategy. ShiftAddLLM affords substantial enhancements in reminiscence and vitality effectivity, demonstrating its potential to make superior LLMs extra accessible and sensible for a wider vary of purposes. This work represents a essential step ahead in addressing the deployment challenges of large-scale AI fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 44k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s captivated with knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.