Doc understanding is a essential area that focuses on changing paperwork into significant info. This includes studying and deciphering textual content and understanding the format, non-textual components, and textual content type. The flexibility to grasp spatial association, visible clues, and textual semantics is crucial for precisely extracting and deciphering info from paperwork. This area has gained vital significance with the appearance of huge language fashions (LLMs) and the growing use of doc photographs in numerous purposes.
The first problem addressed on this analysis is the efficient extraction of knowledge from paperwork that include a mixture of textual and visible components. Conventional text-only fashions typically need assistance deciphering spatial preparations and visible components, leading to incomplete or inaccurate understanding. This limitation is especially evident in duties comparable to Doc Visible Query Answering (DocVQA), the place understanding the context requires seamlessly integrating visible and textual info.
Current strategies for doc understanding sometimes depend on Optical Character Recognition (OCR) engines to extract textual content from photographs. Nonetheless, these strategies might enhance their capacity to include visible clues and the spatial association of textual content, that are essential for complete doc understanding. For example, in DocVQA, the efficiency of text-only fashions is considerably decrease in comparison with fashions that may course of each textual content and pictures. The analysis highlighted the necessity for fashions to combine these components to enhance accuracy and efficiency successfully.
Researchers from Snowflake evaluated numerous configurations of GPT-4 fashions, together with integrating exterior OCR engines with doc photographs. This strategy goals to boost doc understanding by combining OCR-recognized textual content with visible inputs, permitting the fashions to concurrently course of each varieties of info. The research examined totally different variations of GPT-4, such because the TURBO V mannequin, which helps high-resolution photographs and in depth context home windows as much as 128k tokens, enabling it to deal with advanced paperwork extra successfully.
The proposed methodology was evaluated utilizing a number of datasets, together with DocVQA, InfographicsVQA, SlideVQA, and DUDE. These datasets symbolize many doc varieties, from text-intensive to vision-intensive and multi-page paperwork. The outcomes demonstrated vital efficiency enhancements, notably when textual content and pictures have been used. For example, the GPT-4 Imaginative and prescient Turbo mannequin achieved an ANLS rating of 87.4 on DocVQA and 71.9 on InfographicsVQA when each OCR textual content and pictures have been supplied as enter. These scores are notably larger than these achieved by text-only fashions, highlighting the significance of integrating visible info for correct doc understanding.
The analysis additionally supplied an in depth evaluation of the mannequin’s efficiency on various kinds of enter proof. For instance, the research discovered that OCR-provided textual content considerably improved outcomes without spending a dime textual content, kinds, lists, and tables in DocVQA. In distinction, the development was much less pronounced for figures or photographs, indicating that the mannequin advantages extra from text-rich components structured inside the doc. The evaluation revealed a primacy bias, with the mannequin performing higher when related info was situated at the start of the enter doc.
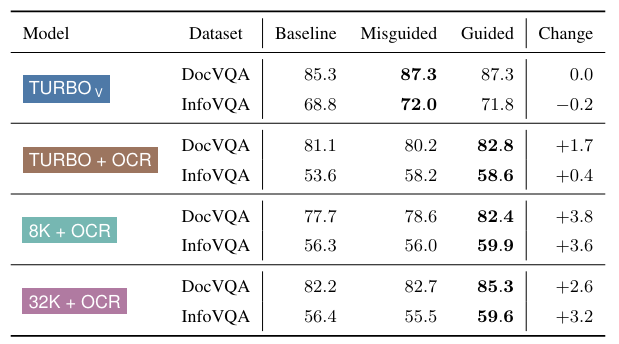
Additional analysis confirmed that the GPT-4 Imaginative and prescient Turbo mannequin outperformed heavier text-only fashions in most duties. The most effective efficiency was achieved with high-resolution photographs (2048 pixels on the longer aspect) and OCR textual content. For instance, on the SlideVQA dataset, the mannequin scored 64.7 with high-resolution photographs, in comparison with decrease scores with lower-resolution photographs. This highlights the significance of picture high quality and OCR accuracy in enhancing doc understanding efficiency.

In conclusion, the analysis superior doc understanding by demonstrating the effectiveness of integrating OCR-recognized textual content with doc photographs. The GPT-4 Imaginative and prescient Turbo mannequin carried out superior on numerous datasets, reaching state-of-the-art leads to duties requiring textual and visible comprehension. This strategy addresses the restrictions of text-only fashions and gives a extra complete understanding of paperwork. The findings underscore the potential for improved accuracy in deciphering advanced paperwork, paving the best way for simpler and dependable doc understanding methods.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Overlook to affix our 44k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.