
Giant language fashions (LLMs) have achieved outstanding success throughout varied domains, however coaching them centrally requires huge information assortment and annotation efforts, making it expensive for particular person events. Federated studying (FL) has emerged as a promising answer, enabling collaborative coaching of LLMs on decentralized information whereas preserving privateness (FedLLM). Though frameworks like OpenFedLLM, FederatedScope-LLM, and FedML-LLM have been developed together with strategies tackling information high quality, mental property, privateness, and useful resource constraints in FedLLM, a major problem stays the shortage of sensible benchmarks. Present works assemble synthetic FL datasets by partitioning centralized datasets, failing to seize properties of real-world cross-user information.
Quite a few strategies have been proposed to deal with information heterogeneity in federated studying, a significant problem the place shoppers’ datasets come from totally different distributions. These embrace regularization, gradient correction, function alignment, adjusting aggregation weights, introducing momentum, and leveraging pre-trained fashions. Whereas FedLLM has gained traction lately, with frameworks like OpenFedLLM, FederatedScope-LLM, FedML-LLM, and strategies like FedbiOT for mannequin property safety and FFA-LoRA for differential privateness, a major limitation persists. Earlier works consider artificially crafted federated datasets by partitioning centralized datasets, failing to seize the complexities of real-world cross-user information.
Researchers from Shanghai Jiao Tong College, Tsinghua College, and Shanghai AI Laboratory suggest FedLLM-Bench, the primary sensible benchmark for FedLLM. It affords a complete testbed with 4 datasets: Fed-Aya (multilingual instruction tuning), Fed-WildChat (multi-turn chat instruction tuning), Fed-ChatbotIT (single-turn chat instruction tuning), and Fed-ChatbotPA (desire alignment). These datasets are naturally cut up by real-world person IDs throughout 38 to 747 shoppers, capturing sensible federated properties like cross-device information partitioning. The datasets exhibit range in languages, information high quality, amount, sequence lengths, and person preferences, mirroring real-world complexities. FedLLM-Bench integrates these datasets with 8 baseline strategies and 6 analysis metrics to facilitate technique comparisons and exploration of recent analysis instructions.
The FedLLM-Bench is launched from 4 views: coaching strategies, datasets, dataset evaluation, and analysis metrics. For coaching strategies, it covers federated instruction tuning and desire alignment duties utilizing parameter-efficient LoRA fine-tuning together with 8 baseline FL strategies like FedAvg, FedProx, SCAFFOLD, FedAvgM, FedAdagrad, FedYogi, and FedAdam. The benchmark contains 4 various datasets: Fed-Aya (multilingual instruction tuning), Fed-ChatbotIT, Fed-WildChat, and Fed-ChatbotPA, capturing sensible properties like diverse languages, high quality, amount, lengths, and person preferences. Intensive dataset evaluation reveals inter/intra-dataset diversities in features like size, directions, high quality, embeddings, and amount. The analysis makes use of 6 metrics – 4 open-ended (MT-Bench, Vicuna bench, AdvBench, Ref-GPT4) and a pair of close-ended (MMLU, HumanEval).
The benchmark evaluates the carried out strategies throughout various datasets. On the multilingual Fed-Aya, most federated strategies outperform native coaching on common, although no single technique dominates all languages, highlighting alternatives for language personalization. For Fed-ChatbotIT, all federated approaches improve instruction-following capacity over native coaching with out compromising basic capabilities, with FedAdagrad performing finest total. On Fed-WildChat for single and multi-turn conversations, federated strategies constantly surpass native coaching, with FedAvg proving the best for multi-turn. For Fed-ChatbotPA desire alignment, federated coaching improves instruction-following and security in comparison with native, with FedAvgM, FedProx, SCAFFOLD, and FedAvg being prime performers. Throughout datasets, federated studying demonstrates clear advantages over particular person coaching by using collaborative information.
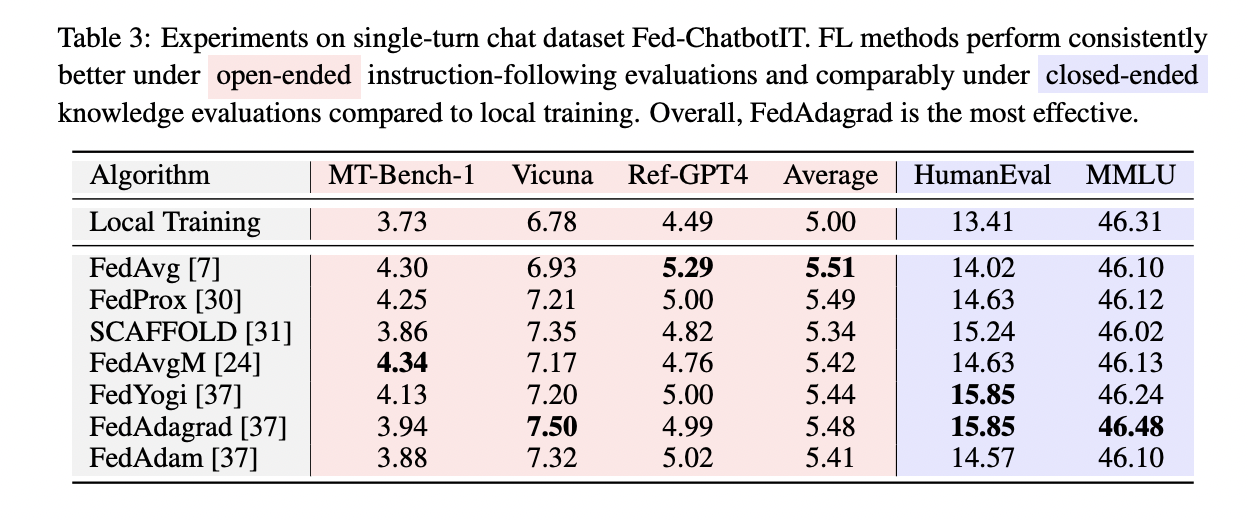
On this research, researchers introduce FedLLM-Bench, the primary sensible benchmark for FedLLM. The core contribution is a set of 4 various datasets spanning instruction tuning and desire alignment duties, exhibiting real-world properties like diverse languages, information high quality, amount, instruction types, sequence lengths, embeddings, and person preferences throughout 38 to 747 shoppers. Built-in with eight coaching strategies, 4 coaching datasets, and 6 analysis metrics, in depth experiments on FedLLM-Bench benchmark classical federated approaches and discover analysis instructions like cross-lingual collaboration and differential privateness. By offering a complete, sensible testbed mirroring real-world complexities, FedLLM-Bench goals to cut back effort, allow truthful comparisons, and propel progress within the rising space of FedLLM. This well timed benchmark can drastically profit the analysis neighborhood engaged on collaborative, privacy-preserving coaching of enormous language fashions.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 44k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


