
Latest developments in massive language fashions (LLMs) have considerably remodeled the sphere of pure language processing (NLP), however their efficiency on present benchmarks has begun to plateau. This stagnation makes it troublesome to discern variations in mannequin capabilities, hindering progress in AI analysis. Benchmarks just like the Huge Multitask Language Understanding (MMLU) have performed an important position in pushing the boundaries of what AI can obtain in language comprehension and reasoning throughout various domains. Nevertheless, the necessity for more difficult and discriminative benchmarks has develop into obvious as fashions enhance. The efficiency saturation on these benchmarks limits the power to successfully consider newer, extra superior fashions. Moreover, the present benchmarks usually function questions which might be predominantly knowledge-driven with restricted reasoning necessities, resulting in inflated efficiency metrics and lowered robustness attributable to sensitivity to immediate variations.
Present strategies, equivalent to the unique MMLU and different benchmarks like GLUE, SuperGLUE, and BigBench, have performed pivotal roles in advancing language understanding duties. Nevertheless, these benchmarks primarily deal with knowledge-driven questions with restricted reasoning necessities, resulting in efficiency saturation amongst top-tier fashions like GPT-4, Gemini, and Claude. These strategies additionally exhibit non-robustness to minor immediate variations, leading to vital fluctuations in mannequin scores and overestimating LLMs’ true efficiency. The everyday multiple-choice query format, usually restricted to 4 choices, fails to distinguish carefully performing techniques and doesn’t adequately problem the fashions’ reasoning capabilities.
Researchers from the College of Waterloo, the College of Toronto, and Carnegie Mellon College suggest a brand new benchmark/leaderboard, MMLU-Professional, which addresses these limitations by incorporating more difficult, reasoning-intensive duties and growing the variety of distractor choices from three to 9. This benchmark spans 14 various domains, encompassing over 12,000 questions, thus offering a broader and extra discriminative analysis. MMLU-Professional additionally includes a two-round professional assessment course of to scale back dataset noise and improve query high quality. This novel strategy considerably raises the benchmark’s problem stage and robustness, making it higher suited to assessing the superior reasoning capabilities of state-of-the-art LLMs.
MMLU-Professional’s dataset development includes integrating questions from varied high-quality sources, together with the unique MMLU, STEM web sites, TheoremQA, and SciBench, making certain a various and difficult query set. The dataset is filtered and refined by a rigorous course of, eradicating overly easy or faulty questions and augmenting the query choices to 10, which necessitates extra discerning reasoning for proper choice. The benchmark additionally evaluates fashions’ efficiency throughout 24 completely different immediate kinds to evaluate robustness and reduce immediate variability impacts. Notable technical elements embrace leveraging the capabilities of superior LLMs like GPT-4-Turbo for possibility augmentation and making certain consistency and accuracy by professional verification.
MMLU-Professional presents vital challenges even for the main fashions. For example, GPT-4o, the strongest mannequin examined, achieved an general accuracy of 72.6%, whereas different top-tier fashions like GPT-4-Turbo reached 63.7%. These outcomes point out substantial room for enchancment, highlighting the benchmark’s effectiveness in differentiating fashions’ reasoning capabilities. The benchmark’s robustness is evidenced by lowered variability in mannequin scores underneath completely different prompts, with a most impression of three.74% in comparison with as much as 10.98% on the unique MMLU. This stability enhances the reliability of evaluations and the benchmark’s utility in advancing AI language understanding capabilities.
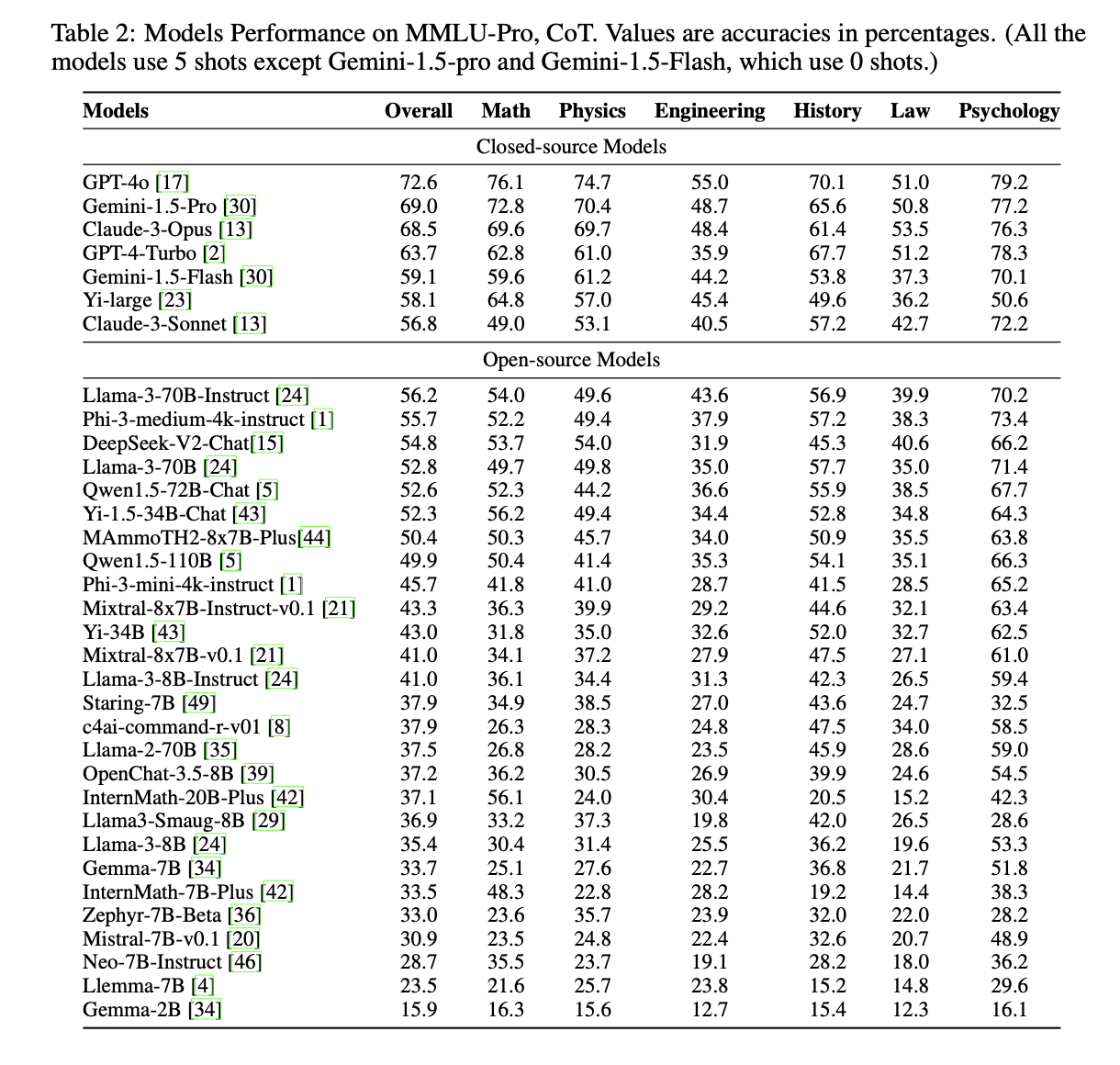
In Conclusion, MMLU-Professional represents a big development in benchmarking LLMs by addressing the constraints of present strategies and enhancing the evaluation of multi-task language understanding and reasoning capabilities. The benchmark introduces extra complicated, reasoning-intensive duties and will increase the variety of distractor choices, considerably enhancing its robustness and discriminative energy. The evaluations present that even top-performing fashions face substantial challenges on MMLU-Professional, indicating its effectiveness in pushing the boundaries of AI capabilities. This benchmark is poised to play an important position sooner or later growth and analysis of LLMs, driving developments in AI analysis by overcoming important challenges in mannequin analysis.
Take a look at the Paper and Leaderboard. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 43k+ ML SubReddit | Additionally, try our AI Occasions Platform
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s keen about information science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


