
Language fashions are elementary to pure language processing (NLP), specializing in producing and comprehending human language. These fashions are integral to purposes corresponding to machine translation, textual content summarization, and conversational brokers, the place the intention is to develop expertise able to understanding and producing human-like textual content. Regardless of their significance, the efficient analysis of those fashions stays an open problem inside the NLP group.
Researchers typically encounter methodological challenges whereas evaluating language fashions, corresponding to fashions’ sensitivity to totally different analysis setups, difficulties in making correct comparisons throughout strategies, and the dearth of reproducibility and transparency. These points can hinder scientific progress and result in biased or unreliable findings in language mannequin analysis, probably affecting the adoption of recent strategies and the route of future analysis.
Present analysis strategies for language fashions typically depend on benchmark duties and automatic metrics corresponding to BLEU and ROUGE. These metrics provide benefits like reproducibility and decrease prices in comparison with handbook human evaluations. Nonetheless, additionally they have notable limitations. As an illustration, whereas automated metrics can measure the overlap between a generated response and a reference textual content, they might want to totally seize the nuances of human language or the correctness of the responses generated by the fashions.
Researchers from EleutherAI and Stability AI, in collaboration with different establishments, launched the Language Mannequin Analysis Harness (lm-eval), an open-source library designed to boost the analysis course of. lm-eval goals to offer a standardized and versatile framework for evaluating language fashions. This instrument facilitates reproducible and rigorous evaluations throughout numerous benchmarks and fashions, considerably enhancing the reliability and transparency of language mannequin assessments.
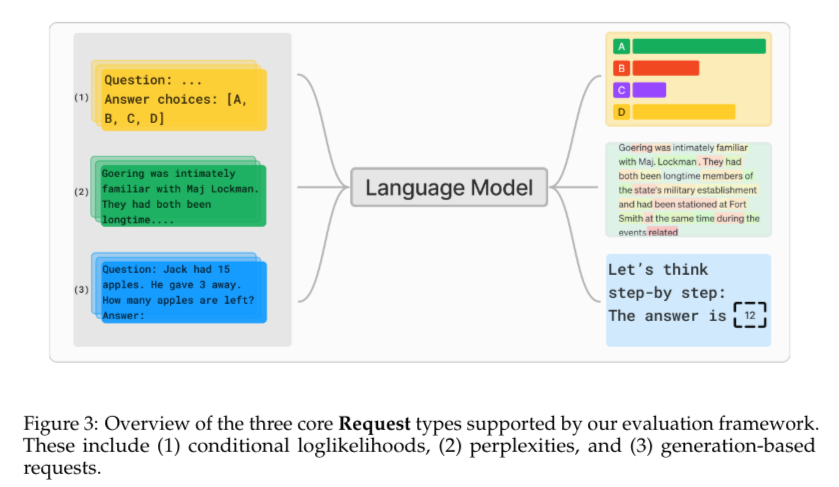
The lm-eval instrument integrates a number of key options to optimize the analysis course of. It permits for the modular implementation of analysis duties, enabling researchers to share and reproduce outcomes extra effectively. The library helps a number of analysis requests, corresponding to conditional loglikelihoods, perplexities, and textual content era, making certain a complete evaluation of a mannequin’s capabilities. For instance, lm-eval can calculate the chance of given output strings primarily based on supplied inputs or measure the common loglikelihood of manufacturing tokens in a dataset. These options make lm-eval a flexible instrument for evaluating language fashions in numerous contexts.
Efficiency outcomes from utilizing lm-eval show its effectiveness in addressing widespread challenges in language mannequin analysis. The instrument helps determine points such because the dependence on minor implementation particulars, which may considerably impression the validity of evaluations. By offering a standardized framework, lm-eval ensures that researchers can carry out evaluations persistently, whatever the particular fashions or benchmarks used. This consistency is essential for truthful comparisons throughout totally different strategies and fashions, finally resulting in extra dependable and correct analysis outcomes.
lm-eval contains options supporting qualitative evaluation and statistical testing, that are important for thorough mannequin evaluations. The library permits for qualitative checks of analysis scores and outputs, serving to researchers determine and proper errors early within the analysis course of. It additionally studies normal errors for many supported metrics, enabling researchers to carry out statistical significance testing and assess the reliability of their outcomes.

In conclusion, Key highlights of the analysis:
- Researchers face vital challenges in evaluating LLMs, together with points with fashions’ sensitivity to analysis setups, difficulties in making correct comparisons throughout strategies, and a scarcity of reproducibility and transparency in outcomes.
- The analysis attracts on three years of expertise evaluating language fashions to offer steering and classes for researchers. It highlights widespread challenges and finest practices to enhance the rigor and communication of ends in the language modeling group.
- Lastly, it introduces lm-eval, an open-source library designed to allow impartial, reproducible, and extensible analysis of language fashions. It addresses the recognized challenges and improves the general analysis course of.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Overlook to hitch our 42k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


