
Giant Language Fashions (LLMs) have pushed outstanding developments throughout numerous Pure Language Processing (NLP) duties. These fashions excel in understanding and producing human-like textual content, enjoying a pivotal position in functions akin to machine translation, summarization, and extra complicated reasoning duties. The development on this area continues to remodel how machines comprehend and course of language, opening new avenues for analysis and growth.
A big problem on this area is the hole between LLMs’ reasoning capabilities and human-level experience. This disparity is especially evident in complicated reasoning duties the place conventional fashions need assistance persistently producing correct outcomes. The problem stems from the fashions’ reliance on majority voting mechanisms, which regularly fail when incorrect solutions dominate the pool of generated responses.
Present work contains Chain-of-Thought (CoT) prompting, which reinforces reasoning by producing intermediate steps. Self-consistency employs a number of reasoning chains, choosing probably the most frequent reply. Complexity-based prompting filters reasoning chains by complexity. DiVeRSe trains verifiers to attain chains, whereas Progressive-Trace Prompting makes use of earlier solutions as hints. These strategies goal to enhance LLMs’ reasoning capabilities by refining the consistency and accuracy of generated solutions.
Researchers from Fudan College, the Nationwide College of Singapore, and the Midea AI Analysis Middle have launched a hierarchical reasoning aggregation framework referred to as AoR (Aggregation of Reasoning). This revolutionary framework shifts the main focus from reply frequency to evaluating reasoning chains. AoR incorporates dynamic sampling, which adjusts the variety of reasoning chains based mostly on the complexity of the duty, thereby enhancing the accuracy and reliability of LLMs’ reasoning capabilities.
The AoR framework operates by way of a two-phase course of: native scoring and global-evaluation. Within the native scoring section, reasoning chains yielding similar solutions are evaluated. The emphasis is on the reasoning course of’s soundness and the reasoning steps’ appropriateness. Chains that rating highest in these evaluations are chosen for the subsequent section. In the course of the world analysis section, the chosen chains are assessed for his or her logical coherence and consistency between the reasoning course of and the corresponding solutions. This rigorous analysis ensures the ultimate reply is derived from probably the most logically sound reasoning chain.
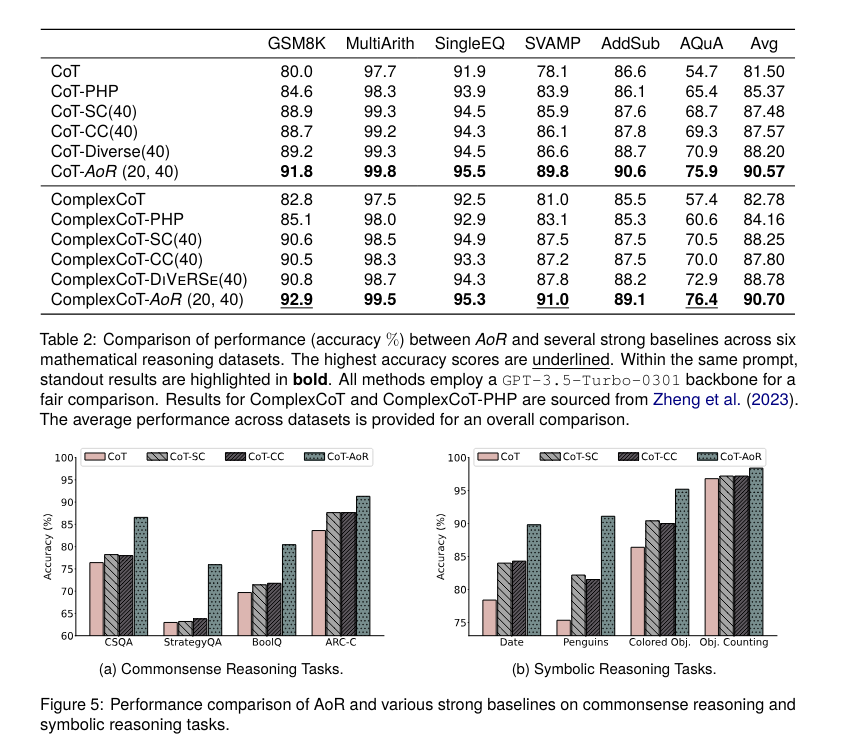
Experimental outcomes show that AoR considerably outperforms conventional ensemble strategies in complicated reasoning duties. As an example, in a collection of difficult reasoning duties, AoR achieved an accuracy enchancment of as much as 7.2% on the AQuA dataset in comparison with the Self-Consistency methodology. The framework additionally adapts properly to numerous LLM architectures, together with GPT-3.5-Turbo-0301, and reveals a superior efficiency ceiling. Notably, AoR’s dynamic sampling functionality successfully balances the efficiency with computational price, lowering the overhead by 20% in comparison with current strategies whereas sustaining excessive accuracy.
As an example, in mathematical reasoning duties, AoR outperformed all baseline approaches throughout six datasets. Below the Chain-of-Thought (CoT) prompting, AoR achieved a mean efficiency enhance of two.37% in comparison with the DiVeRSe methodology. Particularly, the typical efficiency improved by 3.09% in comparison with the Self-Consistency methodology, with vital positive aspects in datasets like GSM8K and MultiArith. Moreover, AoR demonstrated substantial enhancements in commonsense reasoning duties, attaining a mean efficiency enhance of 8.45% over the Self-Consistency methodology.
Dynamic sampling performs an important position in AoR’s success. By leveraging analysis scores from the worldwide analysis section, AoR dynamically adjusts the sampling of reasoning chains based mostly on the mannequin’s confidence. This strategy not solely enhances accuracy but additionally optimizes computational effectivity. For instance, within the AQuA dataset, the dynamic sampling course of decreased the variety of samples wanted, focusing computational efforts on extra complicated queries and making certain exact outcomes.

In conclusion, the AoR framework addresses a essential limitation in LLMs’ reasoning capabilities by introducing a way that evaluates and aggregates reasoning processes. This revolutionary strategy improves the accuracy and effectivity of LLMs in complicated reasoning duties, making vital strides in bridging the hole between machine and human reasoning. The analysis group from Fudan College, the Nationwide College of Singapore, and the Midea AI Analysis Middle has offered a promising answer that enhances the efficiency and reliability of LLMs, setting a brand new benchmark in pure language processing.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to affix our 42k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


