The reminiscence footprint of the key-value (KV) cache could be a bottleneck when serving massive language fashions (LLMs), because it scales proportionally with each sequence size and batch measurement. This overhead limits batch sizes for lengthy sequences and necessitates pricey strategies like offloading when on-device reminiscence is scarce. Moreover, the power to persistently retailer and retrieve KV caches over prolonged intervals is fascinating to keep away from redundant computations. Nonetheless, the scale of the KV cache instantly impacts the associated fee and feasibility of storing and retrieving these persistent caches. As LLM functions more and more demand longer enter sequences, the reminiscence necessities of the KV cache have turn into a crucial consideration in designing environment friendly transformer-based language fashions.
Historically, Multi-Question Consideration (MQA) and Grouped-Question Consideration (GQA) have been employed to cut back the KV cache measurement. The unique transformer structure employed Multi-Head Consideration (MHA), the place every question head attends to the keys and values produced by a definite key/worth head. To scale back the overhead of storing and accessing the KV cache throughout decoding, MQA organizes the question heads into teams, with every group sharing a single key/worth head. GQA generalizes this concept by permitting various numbers of teams. For the reason that KV cache measurement scales solely with the variety of distinct key/worth heads, MQA and GQA successfully scale back the storage overhead. Nonetheless, these strategies have limitations by way of achievable reminiscence discount.
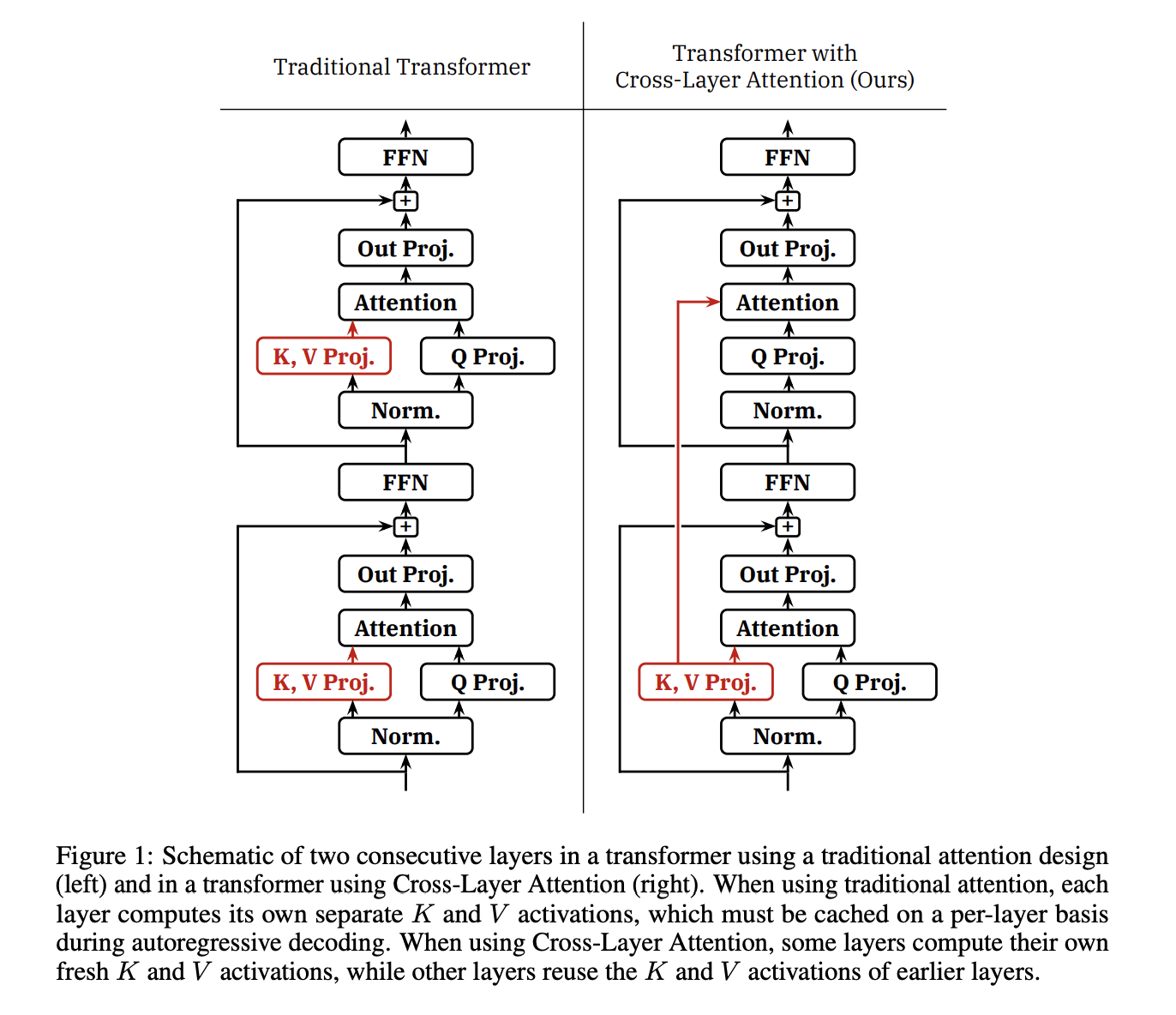
On this paper, researchers from MIT have developed a way known as Cross-Layer Consideration (CLA) that extends the concept of key/worth head sharing. A diagrammatic view of it’s introduced in Determine 1. CLA allows the sharing of key and worth heads not solely inside a layer but in addition throughout adjoining layers. By computing key/worth projections for under a subset of layers and permitting different layers to reuse KV activations from earlier layers, CLA achieves a major discount within the KV cache reminiscence footprint. The discount issue is the same as the sharing issue or barely much less if the sharing issue doesn’t evenly divide the variety of layers.
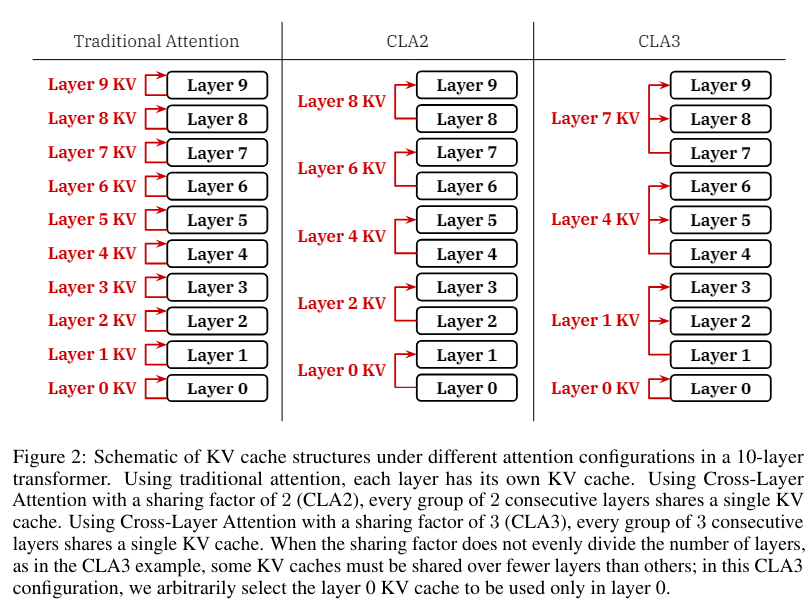
CLA is orthogonal to MQA and GQA, which means it may be mixed with both method. The sharing issue determines the variety of layers that share the output of every KV projection, governing completely different CLA configurations. For instance as proven in Determine 2, CLA2 shares every KV projection amongst a pair of adjoining layers, whereas CLA3 shares it amongst a bunch of three layers.
Let’s now see some advantages of CLA: It reduces the reminiscence footprint of intermediate KV activation tensors materialized throughout coaching, though this discount is often small in comparison with the mannequin’s hidden states and MLP activations. CLA is absolutely suitable with commonplace tensor parallelism strategies for sharding mannequin weights throughout a number of accelerators. Within the presence of pipeline parallelism, both completely different layers sharing a KV cache should be stored in the identical pipeline stage, or KV activations should be communicated between pipeline levels. By decreasing the entire variety of key/worth projection blocks, CLA barely decreases the variety of parameters within the mannequin and the variety of FLOPs required throughout ahead or backward passes. Importantly, CLA allows bigger batch sizes and longer KV cache persistence occasions, which have the potential to enhance inference latency within the context of a full LLM serving stack. Nonetheless, in contrast to MQA and GQA, CLA has no direct impact on the reminiscence bandwidth consumed by the eye mechanism in every decoding step or the latency of the core consideration computation throughout decoding.
To evaluate CLA’s efficacy, the researchers educated transformer-based language fashions from scratch on the 1 billion and three billion parameter scales. Their experiments aimed to reply questions like what accuracy/reminiscence tradeoffs are potential utilizing CLA, the way it compares to plain GQA or MQA, the way it interacts with these strategies, what CLA configurations carry out finest given a set reminiscence finances, and whether or not the results are constant throughout scales.
The important thing findings of the experiment are as follows: CLA allows favorable accuracy/reminiscence tradeoffs in comparison with plain GQA or MQA. A sharing issue of two (CLA2) was simpler than different sharing elements within the experimental regime. CLA was persistently efficient when mixed with MQA to lower KV cache storage. CLA fashions benefited from coaching with greater studying charges than comparable non-CLA fashions. The advantages had been constant throughout each 1B- and 3B-parameter scales.
Quantitatively, MQA-CLA2 persistently achieved the bottom validation perplexity (inside 0.01 factors) for a given KV cache reminiscence finances and mannequin measurement. At each 1B and 3B scales, for MQA fashions with typical head sizes of 64 and 128, making use of CLA2 yielded a 2× KV cache discount whereas incurring, at worst, a really modest (lower than 1% change) degradation in perplexity, and in some instances, even enhancing perplexity. The researchers advocate the MQA-CLA2 recipe to practitioners as a conservative change to present MQA architectures that ship substantial reminiscence overhead reductions with comparatively little threat.
The researchers suspect that the LLMs that may acquire probably the most from CLA are these with extraordinarily lengthy sequences, equivalent to fashions with long-term reminiscence or these utilizing Landmark Consideration, which renders consideration over lengthy contexts extra possible. Nonetheless, they depart end-to-end inference effectivity evaluations of enormous, long-context fashions using CLA as an attention-grabbing downside for future work.
In conclusion, Cross-Layer Consideration (CLA) emerges as an efficient technique for decreasing the KV cache reminiscence storage footprint of transformer fashions by an element of two× with roughly equal perplexity in comparison with present strategies. Based mostly on in depth experimental analysis in opposition to well-tuned baselines at each the 1B- and 3B-parameter scales, CLA advances the Pareto frontier for memory-efficient transformers, making it a promising resolution for memory-constrained functions of enormous language fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 42k+ ML SubReddit
Vineet Kumar is a consulting intern at MarktechPost. He’s presently pursuing his BS from the Indian Institute of Expertise(IIT), Kanpur. He’s a Machine Studying fanatic. He’s keen about analysis and the newest developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.


