
Giant language fashions (LLMs), notably Generative Pre-trained Transformer (GPT) fashions, have demonstrated robust efficiency throughout varied language duties. Nevertheless, challenges persist of their decoder structure, Particularly in time-to-first-token (TTFT) and time-per-output token (TPOT). TTFT, reliant on in depth person context, and TPOT, for fast subsequent token era, have spurred analysis into memory-bound options like sparsification and speculative decoding. Parallelization, via tensor and sequential strategies, addresses compute-bound TTFT however nonetheless lacks optimization for scalable LLM inference attributable to inefficiencies in consideration computation and communication.
Generative LLM inference entails a immediate section, the place preliminary tokens are generated after receiving person context, and an extension section, utilizing cached key-value embeddings to expedite subsequent token era. To reduce TTFT for lengthy contexts, environment friendly KV-cache administration and quick consideration map computation are very important. Numerous optimization approaches, similar to PagedAttention and CacheGen, deal with these challenges. Parallelization strategies like tensor and sequence parallelism intention to optimize compute-bound TTFT, with improvements like KV-Runahead additional enhancing scalability and cargo balancing for improved inference effectivity.
Apple researchers current a parallelization method, KV-Runahead, tailor-made particularly for LLM inference to reduce TTFT. Using the present KV cache mechanism, KV-Runahead optimizes by distributing the KV-cache inhabitants throughout processes, guaranteeing context-level load-balancing. By capitalizing on causal consideration computation inherent in KV-cache, KV-Runahead successfully reduces computation and communication prices, leading to decrease TTFT in comparison with current strategies. Importantly, its implementation entails minimal engineering effort, because it repurposes the KV-cache interface with out important modifications.
KV-Runahead is contrasted with Tensor/Sequence Parallel Inference (TSP), which evenly distributes computation throughout processes. Not like TSP, KV-Runahead makes use of a number of processes to populate KV-caches for the ultimate course of, necessitating efficient context partitioning for load-balancing. Every course of then executes layers, awaiting KV-cache from the previous course of through native communication quite than world synchronization.
Researchers carried out experiments on a single node outfitted with 8× NVidia A100 GPUs, below each excessive (300GB/s) and low (10GB/s) bandwidth situations. KV-Runahead, using FP16 for inference, was in contrast towards Tensor/Sequence Parallelization (TSP) and demonstrated superior efficiency, persistently outperforming TSP in varied eventualities. Totally different variants of KV-Runahead, together with KVR-E with even context partitioning, KVR-S with searched partitioning, and KVR-P with predicted partitioning, have been evaluated for effectivity. KV-Runahead achieves important speedups, notably with longer contexts and extra GPUs, even outperforming TSP on low bandwidth networks. Additionally, KV-Runahead reveals robustness towards non-uniform community bandwidth, showcasing the advantages of its communication mechanism.
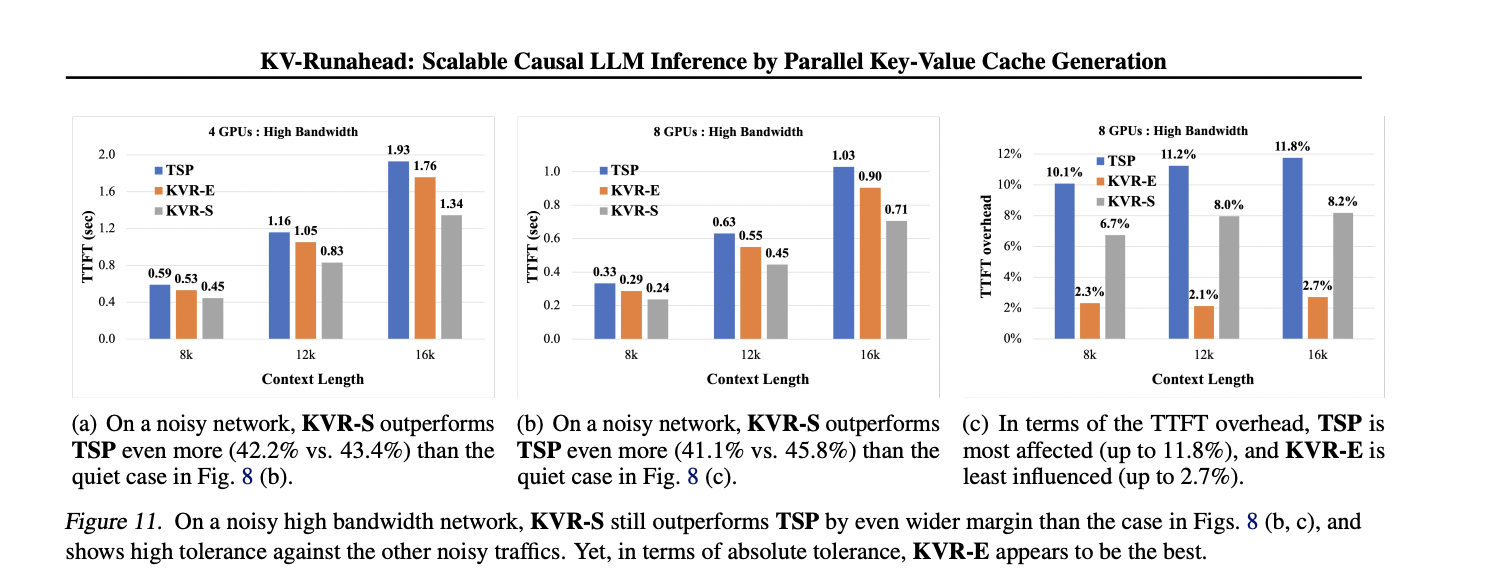
On this work, Apple researchers launched KV-Runahead, an efficient parallel LLM inference technique aimed toward decreasing time-to-first-token. KV cache achieved a big speedup, over 60% speedup within the first token era in comparison with current parallelization strategies. Additionally, KV-Runahead demonstrates elevated resilience in eventualities with non-uniform bandwidth environments.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to affix our 42k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


