
Within the increasing pure language processing area, textual content embedding fashions have turn into elementary. These fashions convert textual info right into a numerical format, enabling machines to know, interpret, and manipulate human language. This technological development helps numerous purposes, from serps to chatbots, enhancing effectivity and effectiveness. The problem on this area entails enhancing the retrieval accuracy of embedding fashions with out excessively rising computational prices. Present fashions need assistance to stability efficiency with useful resource calls for, usually requiring vital computational energy for minimal beneficial properties in accuracy.
Current analysis consists of the E5 mannequin, recognized for its effectivity in web-crawled datasets, and the GTE mannequin, which reinforces textual content embedding applicability by way of multi-stage contrastive studying. The Jina framework focuses on lengthy doc processing, whereas BERT and its variants, like MiniLM and Nomic BERT, optimize for particular duties like effectivity and long-context information dealing with. InfoNCE loss has been pivotal in refining mannequin coaching for higher similarity duties. Furthermore, the FAISS library aids within the environment friendly retrieval of paperwork, streamlining the embedding-based search processes.
Researchers from Snowflake Inc. have launched Arctic-embed fashions, setting a brand new customary for textual content embedding effectivity and accuracy. These fashions distinguish themselves by using a data-centric coaching technique that optimizes retrieval efficiency with out excessively scaling mannequin dimension or complexity. Utilizing in-batch negatives and a classy information filtering system helps the Arctic-embed fashions obtain superior retrieval accuracy in comparison with present options, showcasing their practicality in real-world purposes.
The methodology behind Arctic-embed fashions entails coaching with datasets equivalent to MSMARCO and BEIR, that are famous for his or her complete protection and benchmarking relevance within the area. The fashions vary from small-scale variants with 22 million parameters to the biggest with 334 million; every tuned to optimize efficiency metrics like nDCG@10 on the MTEB Retrieval leaderboard. These fashions leverage a mixture of pre-trained language mannequin backbones and fine-tuning methods, together with arduous unfavorable mining and optimized batch processing, to boost retrieval accuracy.
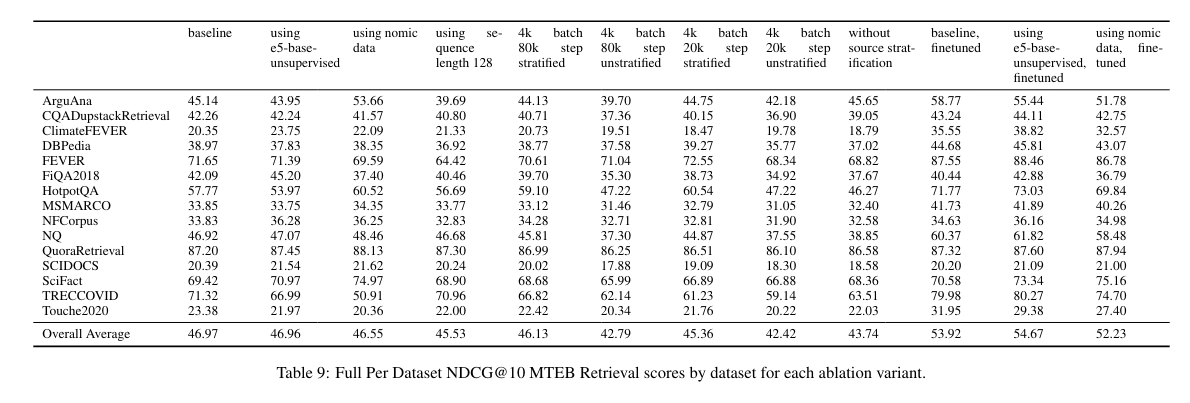
The Arctic-embed fashions achieved excellent outcomes on the MTEB Retrieval leaderboard. Particularly, the nDCG@10 scores for the varied fashions inside this suite ranged impressively, with the Arctic-embed-l mannequin reaching a peak rating of 88.13. This benchmark efficiency signifies a considerable development over prior fashions, underlining the effectiveness of the novel methodologies employed in these fashions. These outcomes underscore the fashions’ functionality to deal with complicated retrieval duties with enhanced accuracy, setting a brand new customary in textual content embedding.
To conclude, the Arctic-embed suite of fashions by Snowflake Inc. represents a major development in textual content embedding expertise. These fashions obtain superior retrieval accuracy with environment friendly computational use by specializing in optimized information filtering and coaching methodologies. The nDCG@10 scores, notably the 88.13 achieved by the biggest mannequin, underscore the sensible advantages of this analysis. This improvement enhances textual content retrieval capabilities and units a benchmark that guides future improvements within the area, making high-performance textual content processing extra accessible and efficient.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Overlook to affix our 42k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


