
Giant language fashions (LLMs) are central to processing huge quantities of information shortly and precisely. They rely critically on the standard of instruction tuning to reinforce their reasoning capabilities. Instruction tuning is crucial because it prepares LLMs to unravel new, unseen issues successfully by making use of realized data in structured eventualities.
Securing high-quality, scalable instruction information stays a principal problem within the area. Earlier strategies, which rely closely on human enter or subtle algorithms for distilling advanced datasets into usable coaching supplies, are sometimes constrained by excessive prices, restricted scalability, and potential biases. These drawbacks necessitate a extra environment friendly technique for buying the huge, various datasets wanted for efficient LLM coaching.
Researchers from Carnegie Mellon College and the College of Waterloo have developed an revolutionary method often called Net-Instruct, which bypasses conventional limitations by sourcing instruction information straight from the Web. This technique exploits the wealthy, various on-line content material, changing it right into a invaluable useful resource for tuning LLMs. The method includes deciding on related paperwork from a broad net corpus, extracting potential instruction-response pairs, and refining these pairs to make sure top quality and relevance for LLM duties.
In addition they construct the MAmmoTH2 mannequin, tuned utilizing the Net-Instruct dataset, showcasing this technique’s effectiveness. The dataset, comprising 10 million instruction-response pairs, is gathered with out the numerous prices related to human information curation or the biases from mannequin distillation strategies. This huge and various dataset has propelled MAmmoTH2 to attain outstanding efficiency enhancements. As an example, MAmmoTH2 demonstrated a surge in accuracy from 11% to 34% on advanced reasoning duties, equivalent to mathematical problem-solving and scientific reasoning, with out particular area coaching.
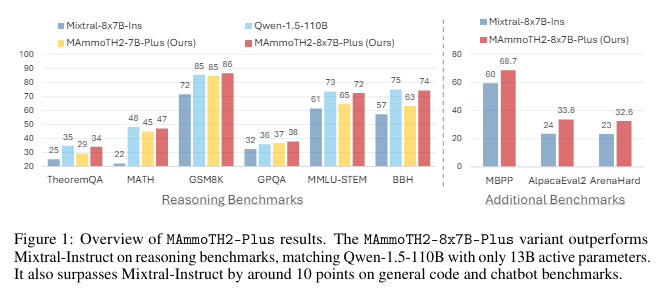
MAmmoTH2-Plus is an enhanced mannequin model that integrates extra public instruction datasets for broader coaching. This mannequin variant has been proven to outperform base fashions on commonplace reasoning persistently benchmarks like TheoremQA and GSM8K, with enhancements in efficiency of as much as 23% in comparison with earlier benchmarks. MAmmoTH2-Plus additionally excelled usually duties, indicating its robust generalization capabilities throughout a spectrum of advanced reasoning and conversational benchmarks.

In conclusion, the Net-Instruct technique and the following growth of the MAmmoTH2 and MAmmoTH2-Plus fashions mark important advances in instruction tuning for LLMs. This method gives a scalable, cost-effective various to conventional information assortment and processing strategies by leveraging the intensive and various on-line educational content material. The success of fashions tuned with this dataset underscores the potential of web-mined instruction information to dramatically improve the reasoning skills of LLMs, broadening their utility scope and setting new benchmarks for information high quality and mannequin efficiency in AI.
Try the Paper and Venture. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 42k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with information science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


