
Quantization, a technique integral to computational linguistics, is important for managing the huge computational calls for of deploying massive language fashions (LLMs). It simplifies information, thereby facilitating faster computations and extra environment friendly mannequin efficiency. Nonetheless, deploying LLMs is inherently advanced because of their colossal measurement and the computational depth required. Efficient deployment methods should steadiness efficiency, accuracy, and computational overhead.
In LLMs, conventional quantization methods convert high-precision floating-point numbers into lower-precision integers. Whereas this course of reduces reminiscence utilization and accelerates computation, it usually incurs important computational overhead. This overhead can degrade mannequin accuracy, because the precision discount can result in substantial losses in information constancy.
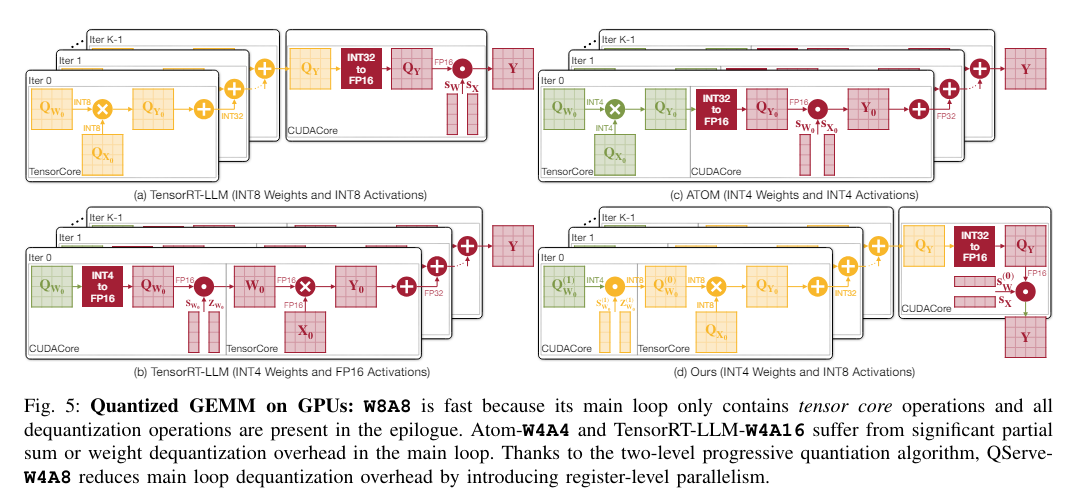
Researchers from MIT, NVIDIA, UMass Amherst, and MIT-IBM Watson AI Lab launched the Quattuor-Octo-Quattuor (QoQ) algorithm, a novel method that refines quantization. This progressive methodology employs progressive group quantization, which mitigates the accuracy losses usually related to normal quantization strategies. By quantizing weights to an intermediate precision and refining them to the goal precision, the QoQ algorithm ensures that every one computations are tailored to the capabilities of current-generation GPUs.
The QoQ algorithm makes use of a two-stage quantization course of. Initially, weights are quantized to eight bits utilizing per-channel FP16 scales; these intermediates are additional quantized to 4 bits. This method allows Normal Matrix Multiplication (GEMM) operations on INT8 tensor cores, enhancing computational throughput and decreasing latency. The algorithm additionally incorporates SmoothAttention, a method that adjusts the quantization of activation keys to optimize efficiency additional.
The QServe system was developed to assist the deployment of the QoQ algorithm. QServe offers a tailor-made runtime setting that maximizes the effectivity of LLMs by exploiting the algorithm’s full potential. It integrates seamlessly with present GPU architectures, facilitating operations on low-throughput CUDA cores and considerably boosting processing pace. This method design reduces the quantization overhead by specializing in compute-aware weight reordering and fused consideration mechanisms, important for sustaining throughput and minimizing latency in real-time purposes.
Efficiency evaluations of the QoQ algorithm point out substantial enhancements over earlier strategies. In testing, QoQ improved the utmost achievable serving throughput of Llama-3-8B fashions by as much as 1.2 instances on NVIDIA A100 GPUs and as much as 1.4 instances on L40S GPUs. Remarkably, on the L40S platform, QServe, a system designed to assist QoQ, achieved throughput enhancements of as much as 3.5 instances in comparison with the identical mannequin on A100 GPUs, considerably decreasing the price of LLM serving.

In conclusion, the examine introduces the QoQ algorithm and QServe system as groundbreaking options to the challenges of deploying LLMs effectively. By addressing the numerous computational overhead and accuracy loss inherent in conventional quantization strategies, QoQ and QServe markedly improve LLM serving throughput. The outcomes from the implementation reveal as much as 2.4 instances sooner processing on superior GPUs, considerably decreasing each the computational calls for and the financial prices related to LLM deployment. This development paves the way in which for broader adoption and simpler use of huge language fashions in real-world purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 42k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.


