
Graph Neural Networks (GNNs) are essential in processing knowledge from domains reminiscent of e-commerce and social networks as a result of they handle complicated constructions. Historically, GNNs function on knowledge that matches inside a system’s principal reminiscence. Nevertheless, with the rising scale of graph knowledge, many networks now require strategies to deal with datasets that exceed reminiscence limits, introducing the necessity for out-of-core options the place knowledge resides on disk.
Regardless of their necessity, current out-of-core GNN programs battle to steadiness environment friendly knowledge entry with mannequin accuracy. Present programs face a trade-off: both endure from gradual enter/output operations on account of small, frequent disk reads or compromise accuracy by dealing with graph knowledge in disconnected chunks. As an example, whereas pioneering, these challenges have restricted earlier options like Ginex and MariusGNN, displaying vital drawbacks in coaching velocity or accuracy.
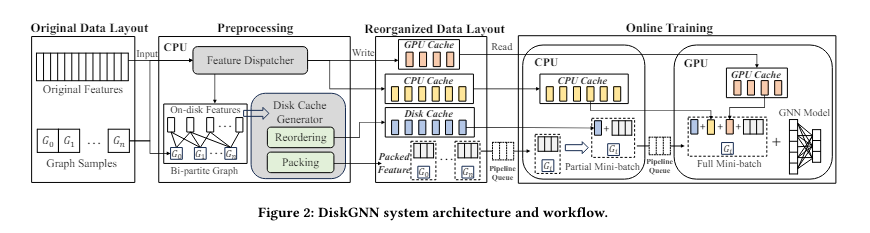
The DiskGNN framework, developed by researchers from Southern College of Science and Know-how, Shanghai Jiao Tong College, Centre for Perceptual and Interactive Intelligence, AWS Shanghai AI Lab, and New York College, emerges as a transformative answer particularly designed to optimize the velocity and accuracy of GNN coaching on giant datasets. This technique makes use of an progressive offline sampling approach that prepares knowledge for fast entry throughout coaching. By preprocessing and arranging graph knowledge based mostly on anticipated entry patterns, DiskGNN reduces pointless disk reads, considerably enhancing coaching effectivity.
The structure of DiskGNN is constructed round a multi-tiered storage strategy that cleverly makes use of GPU and CPU reminiscence alongside disk storage. This construction ensures that regularly accessed knowledge is stored nearer to the computation layer, considerably dashing up the coaching course of. As an example, in benchmark exams, DiskGNN demonstrated a speedup of over eight occasions in comparison with baselines, with coaching epochs averaging round 76 seconds in comparison with 580 seconds for programs like Ginex.
Efficiency evaluations additional illustrate DiskGNN’s efficacy. The system accelerates the GNN coaching course of and maintains excessive mannequin accuracy. For instance, in exams involving the Ogbn-papers100M graph dataset, DiskGNN matched or exceeded the perfect mannequin accuracies of current programs whereas considerably lowering the common epoch time and disk entry time. Particularly, DiskGNN managed to take care of an accuracy of roughly 65.9% whereas lowering the common disk entry time to only 51.2 seconds, in comparison with 412 seconds in earlier programs.
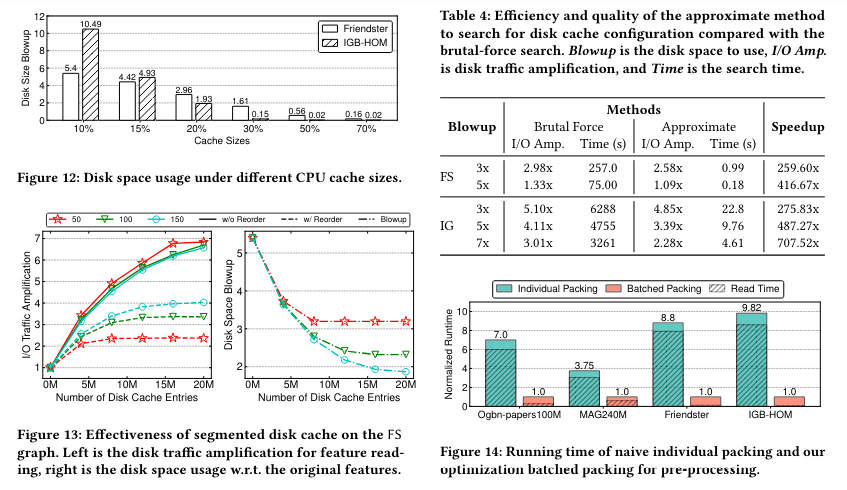
DiskGNN’s design minimizes the everyday amplification of learn operations inherent in disk-based programs. The system successfully avoids the everyday situation the place every coaching step requires a number of, small-scale learn operations by organizing node options into contiguous blocks on the disk. This reduces the load on the storage system and reduces the time spent ready for knowledge, thus optimizing the general coaching pipeline.
In conclusion, DiskGNN, which addresses the twin challenges of information entry velocity and mannequin accuracy, units a brand new commonplace for out-of-core GNN coaching. DiskGNN’s strategic knowledge administration and progressive structure permit it to outperform current options, providing a quicker, extra correct strategy to coaching graph neural networks. This makes it a useful software for researchers and industries working with in depth graph datasets, the place efficiency and accuracy are paramount.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Overlook to hitch our 42k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.


