
Massive Language Fashions (LLMs) have demonstrated outstanding skills in producing human-like textual content, answering questions, and coding. Nevertheless, they face hurdles requiring excessive reliability, security, and moral adherence. Reinforcement Studying from Human Suggestions (RLHF), or Desire-based Reinforcement Studying (PbRL), emerges as a promising answer. This framework has proven vital success in fine-tuning LLMs to align with human preferences, enhancing their usefulness.
Current RLHF approaches, like InstructGPT, depend on express or implicit reward fashions, e.g., the Bradley-Terry mannequin. Latest analysis explores direct desire chances to higher signify human preferences. Some researchers formulate RLHF as discovering Nash equilibriums in constant-sum video games, proposing mirror descent and Self-play Desire Optimization (SPO) strategies. Direct Nash Optimization (DNO) was additionally launched primarily based on win charge gaps, but its sensible implementation nonetheless depends on iterative DPO frameworks.
Researchers from the College of California, Los Angeles and Carnegie Mellon College introduce a sturdy self-play framework, Self-Play Desire Optimization (SPPO), for language mannequin alignment addressing RLHF challenges. It presents provable ensures for fixing two-player constant-sum video games and scalability for big language fashions. In formulating RLHF as such a sport, the target is to establish the Nash equilibrium coverage, guaranteeing persistently most well-liked responses. They suggest an adaptive algorithm primarily based on multiplicative weights, using a self-play mechanism the place the coverage fine-tunes itself on artificial knowledge annotated by the desire mannequin.
The self-play framework goals to resolve two-player constant-sum video games effectively and at scale for big language fashions. It adopts an iterative framework primarily based on multiplicative weight updates and a self-play mechanism. The algorithm asymptotically converges to the optimum coverage, figuring out the Nash equilibrium. Theoretical evaluation ensures convergence, offering provable ensures. In comparison with present strategies like DPO and IPO, SPPO demonstrates improved convergence and addresses knowledge sparsity points effectively.
The researchers consider fashions utilizing GPT-4 for automated analysis, presenting outcomes on AlpacaEval 2.0 and MT-Bench. SPPO fashions persistently enhance throughout iterations, with SPPO Iter3 displaying the best win charge. In comparison with DPO and IPO, SPPO achieves superior efficiency and successfully controls output size. Take a look at-time reranking with the PairRM reward mannequin persistently improves mannequin efficiency with out over-optimization. SPPO outperforms many state-of-the-art chatbots on AlpacaEval 2.0 and stays aggressive with GPT-4 on MT-Bench.
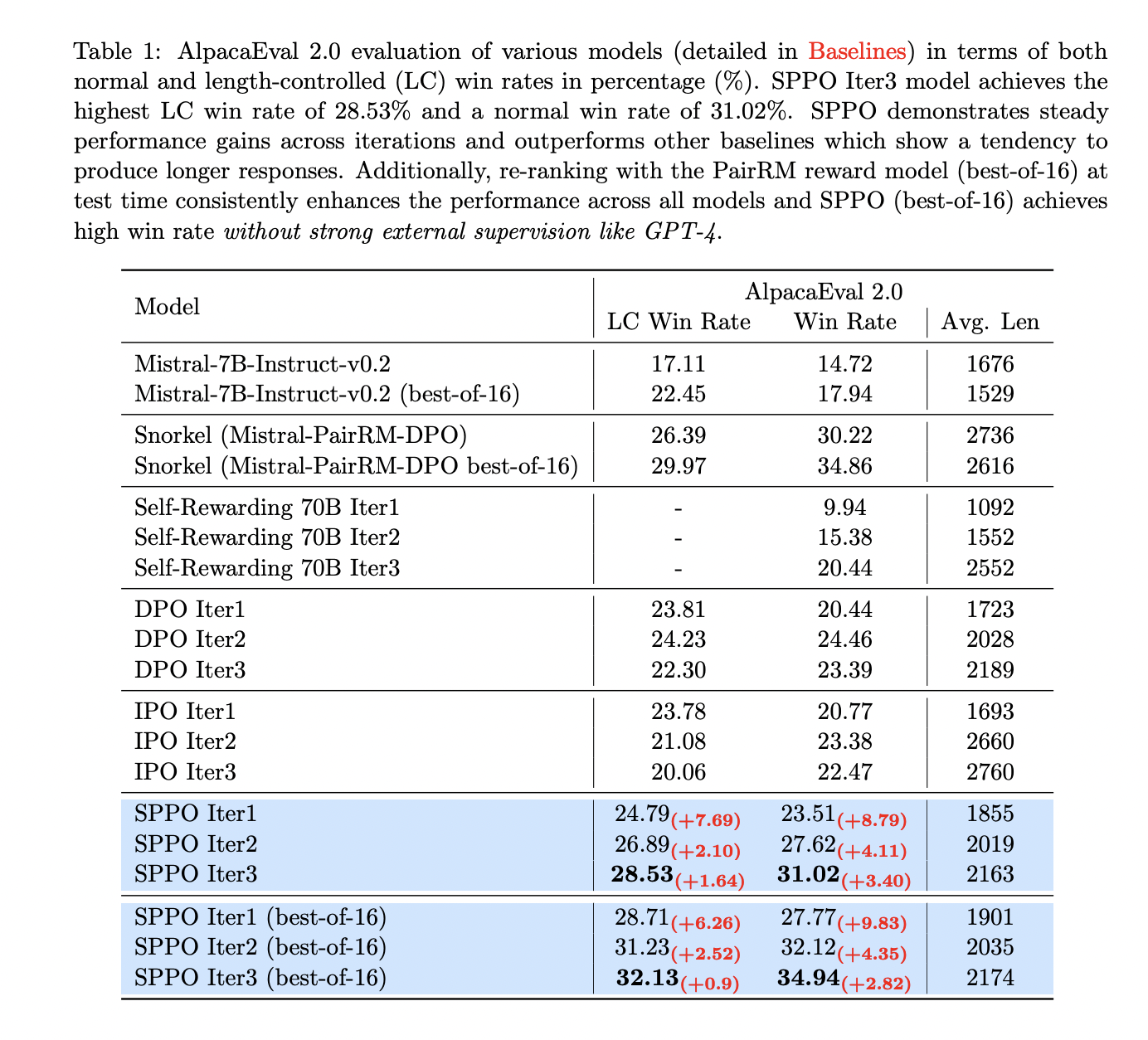
To conclude, the paper introduces Self-Play Desire Optimization (SPPO), a sturdy methodology for fine-tuning LLMs utilizing Human/AI Suggestions. By using self-play in a two-player sport and a preference-based studying goal, SPPO considerably improves over present strategies like DPO and IPO throughout numerous benchmarks. Integrating a desire mannequin and batched estimation, SPPO aligns LLMs intently with human preferences, addressing points like “size bias” reward hacking. These findings recommend SPPO’s potential for enhancing generative AI system alignment, advocating for its broader adoption in LLMs and past.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 41k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


