
Massive Language Fashions (LLMs) symbolize a big leap in synthetic intelligence, providing sturdy pure language understanding and era capabilities. These superior fashions can carry out varied duties, from aiding digital assistants to producing complete content material and conducting in-depth knowledge evaluation. Regardless of their spectacular vary of functions, LLMs face a important problem in producing factually correct responses, typically producing deceptive or inaccurate data as a result of broad spectrum of information they course of. This can be a notable concern, particularly contemplating their meant use in offering dependable data.
One of many predominant points with LLMs is their tendency to hallucinate, which implies they generate fabricated or incorrect data. This downside is primarily rooted within the supervised fine-tuning (SFT) and reinforcement studying (RL) processes, which unintentionally encourage these fashions to supply deceptive outputs. As LLMs are designed to reply to numerous consumer queries, it’s essential to make sure they produce correct data to forestall the unfold of misinformation. The problem lies in aligning these fashions to ship factually appropriate responses with out compromising their instruction-following means.
Conventional strategies like SFT and RL with human suggestions (RLHF) have targeted on enhancing the flexibility of LLMs to observe directions successfully. Nevertheless, these strategies are inclined to prioritize extra detailed and longer responses, which regularly results in elevated hallucinations. Analysis has proven that fine-tuning fashions with new or unfamiliar data exacerbate this downside, making them extra vulnerable to producing unreliable content material. In consequence, there’s a urgent want for approaches that may enhance the factual accuracy of those fashions with out negatively affecting their instruction-following capabilities.
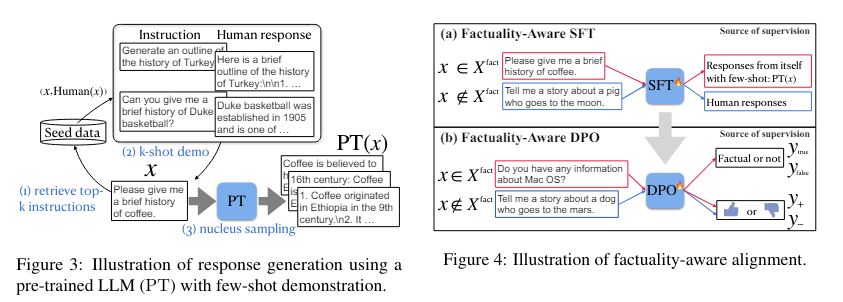
Researchers from the College of Waterloo, Carnegie Mellon College, and Meta AI have launched a novel strategy referred to as Factuality-Conscious Alignment (FLAME) to sort out this concern. This methodology particularly addresses the problem of bettering factual accuracy in LLMs by a mixture of factuality-aware SFT and RL with direct desire optimization (DPO). FLAME’s modern strategy focuses on crafting coaching knowledge that encourages fashions to supply extra factual responses whereas utilizing specialised reward features to steer them towards correct outputs. They performed a pilot examine to guage the effectiveness of this strategy utilizing a biography era activity. The examine revealed that LLMs skilled on their very own generated knowledge are extra dependable than these skilled on extra factual responses generated by different fashions.
FLAME’s two-step strategy begins by figuring out fact-based directions that require factual responses. As soon as these directions are recognized, the tactic fine-tunes the mannequin utilizing a factuality-aware SFT technique, which prevents the mannequin from being skilled on unfamiliar data that might result in hallucination. The second step includes implementing DPO, which makes use of factuality-specific rewards to distinguish between fact-based and non-fact-based directions, guiding the LLMs to supply extra dependable responses. On this approach, FLAME helps LLMs keep their instruction-following means whereas considerably decreasing the probability of hallucination.
The analysis confirmed that this strategy considerably improved LLMs’ factual accuracy, reaching a +5.6-point enhance in FActScore in comparison with customary alignment processes with out sacrificing instruction-following capabilities. This was validated utilizing Alpaca Eval, a benchmark that assesses a mannequin’s means to observe directions, and the Biography dataset, which evaluates the factuality of generated content material. The examine used 805 instruction-following duties from Alpaca Eval to measure the win price of fashions utilizing FLAME, demonstrating the tactic’s effectiveness in balancing factuality with the flexibility to observe directions.
In conclusion, FLAME provides a promising resolution to one of the crucial important challenges dealing with LLMs as we speak. By refining the coaching and optimization course of, the analysis staff has developed a technique that permits LLMs to observe directions successfully whereas considerably decreasing the danger of hallucination. This makes them higher fitted to functions the place accuracy is paramount, permitting for extra dependable AI-driven options sooner or later.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Overlook to affix our 41k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.


