
The event of pure language processing has been considerably propelled by the developments in giant language fashions (LLMs). These fashions have showcased exceptional efficiency in duties like translation, query answering, and textual content summarization, proving their effectivity in producing high-quality textual content. Nonetheless, regardless of their effectiveness, one main limitation stays their sluggish inference pace, which hinders their use in real-time purposes. This problem predominantly arises from the reminiscence bandwidth bottleneck quite than an absence of computational energy, resulting in researchers in search of progressive methods to hurry up their inference course of.
The important thing situation lies within the standard speculative decoding strategies that depend on coaching separate draft fashions for quicker textual content era. These strategies usually generate a number of tokens in parallel to speed up the general course of. Though efficient, they arrive with vital coaching prices and excessive latency. The excessive inference latency related to these strategies is primarily because of their dependence on exterior drafter fashions, which introduce further computations that decelerate the method.
Present strategies like Medusa and Lookahead have been designed to introduce extra environment friendly speculative decoding approaches. These approaches intention to coach smaller draft fashions that may work alongside the primary language mannequin. Nonetheless, these strategies nonetheless face latency points, because the draft fashions require substantial computational sources and parameter updates. This slows down the general inference course of, lowering the effectiveness of the acceleration.
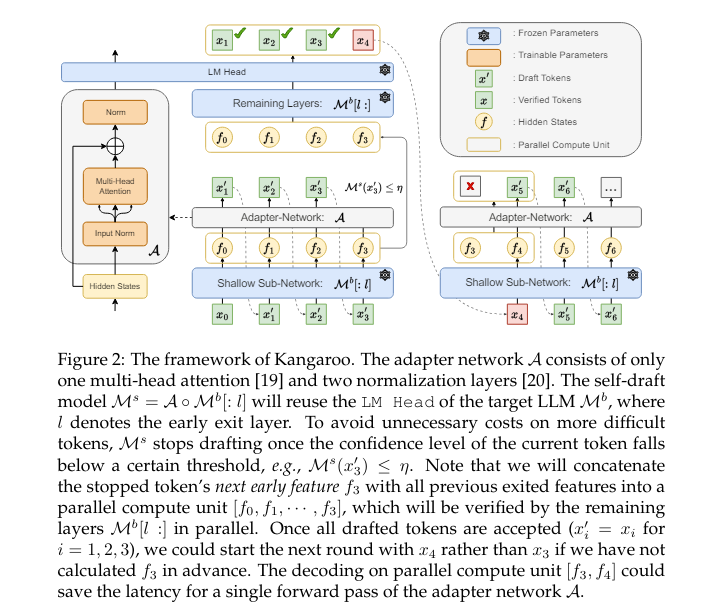
Huawei Noah’s Ark Lab researchers have developed an progressive framework named Kangaroo. This novel technique addresses the difficulty of excessive latency in speculative decoding by introducing a lossless self-speculative decoding framework. In contrast to conventional strategies that depend on exterior drafter fashions, Kangaroo makes use of a hard and fast shallow LLM sub-network because the draft mannequin. Researchers prepare a light-weight adapter module that connects the 2 to bridge the hole between the sub-network and the total mannequin, enabling environment friendly and correct token era.
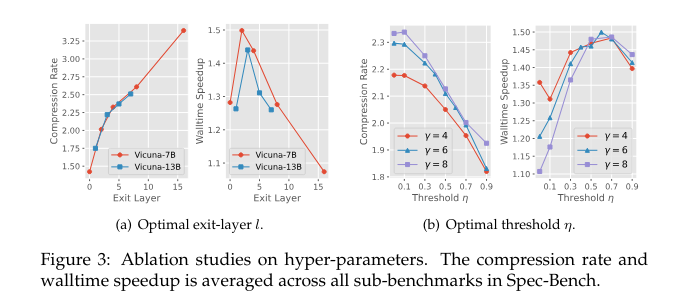
Kangaroo employs an early-exiting mechanism to reinforce its effectivity additional. This mechanism halts the small mannequin’s prediction as soon as the arrogance degree of the present token falls beneath a selected threshold, lowering pointless computational latency. The adapter module utilized in Kangaroo includes a multi-head consideration mechanism and two normalization layers, offering ample capability to make sure high-quality token era. The early exiting layer balances the token acceptance price and drafting effectivity trade-offs. The dynamic mechanism of the Kangaroo permits for extra environment friendly token era by using parallel computing and avoiding pointless computations.
In depth experiments performed utilizing Spec-Bench reveal the Kangaroo’s effectiveness. It achieved a speedup ratio of as much as 1.7× in comparison with different strategies, utilizing 88.7% fewer further parameters than Medusa, which has 591 million further parameters. Kangaroo’s vital enhancements in speedup ratio are attributed to its double early-exit mechanism and the environment friendly design of the adapter community. This progressive framework considerably reduces latency, making it extremely appropriate for real-time pure language processing purposes.
In conclusion, Kangaroo is a pioneering resolution in accelerating LLMs’ inference pace. Utilizing a hard and fast shallow sub-network from the LLM as a draft mannequin, Kangaroo eliminates the necessity for expensive and time-consuming exterior drafter fashions. Introducing the early-exit mechanism additional enhances the pace and effectivity of the inference course of, enabling Kangaroo to outperform different speculative decoding strategies. With as much as a 1.7× speedup and a drastic discount in further parameters, Kangaroo presents a promising method to enhancing the effectivity of huge language fashions. It units a brand new normal in real-time pure language processing by considerably lowering latency with out compromising accuracy.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 40k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.


