
The arrival of generative synthetic intelligence (AI) marks a big technological leap, enabling the creation of latest textual content, photographs, movies, and different media by studying from huge datasets. Nevertheless, this progressive functionality brings forth substantial copyright issues, as it could make the most of and repurpose the inventive works of authentic authors with out consent.
This analysis addresses the potential for copyright infringement by generative AI applied sciences, which may produce outputs that may mimic and exchange authentic human-made content material. Such infringement dangers undermine the financial rights of authentic content material creators and pose authorized challenges in inventive industries.
Historically, approaches to mitigate these dangers have concerned altering the coaching mechanisms of AI fashions to reduce the prospect of producing copyright-infringing outputs. These strategies, nonetheless, typically compromise the effectiveness of AI purposes by excluding high-quality however copyrighted information from coaching units.
The analysis group from Princeton College, Columbia College, Harvard College, and the College of Pennsylvania proposes a novel financial framework that makes use of rules from cooperative sport concept to ascertain a good royalty distribution system. This technique assesses the contributions of particular person copyright holders to AI-generated content material based mostly on the probabilistic nature of generative fashions. It employs the Shapley worth, a way from sport concept, to assign royalties pretty, making certain every contributor is compensated in line with their information’s utility in coaching the AI.
This framework is demonstrated by numerical experiments involving numerous information units, together with these from WikiArt and FlickrLogo-27. These experiments assess the mannequin’s capability to allocate royalties precisely by analyzing the AI’s efficiency when producing content material like art work and logos, which depend on copyrighted and non-copyrighted coaching information. For instance, in exams involving the WikiArt dataset, the utility scores calculated by the framework successfully mirrored the contributions of various artists’ kinds to the AI-generated art work.
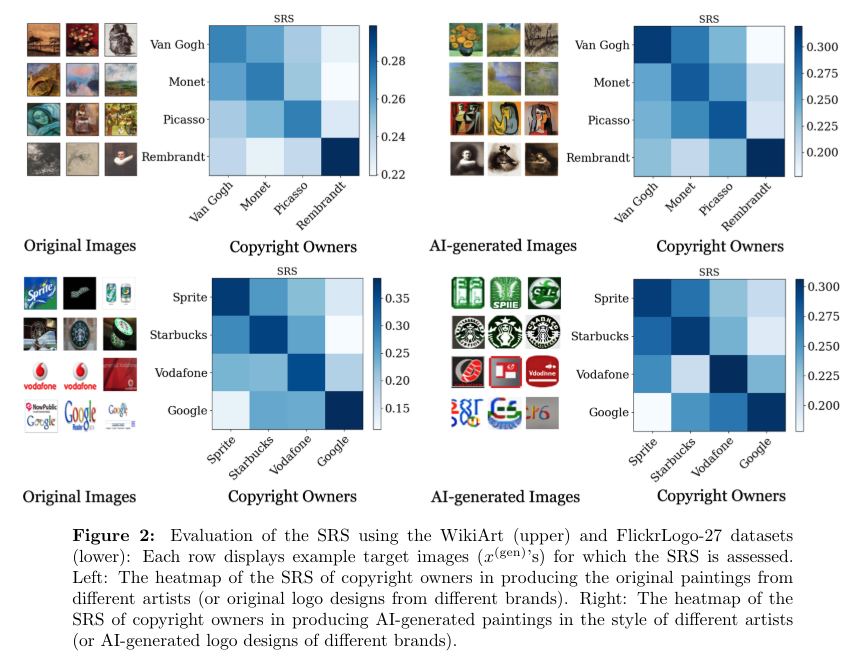
The analysis outlines how incorporating a broader vary of coaching information with out infringing on copyrights enhances the AI’s functionality. For example, when a generative mannequin educated on a subset of information achieved a utility rating of 0.85, it advised a big contribution by that information subset in direction of the generated content material, in comparison with a baseline mannequin.
The analysis additionally critically examines the complexities of implementing such an financial mannequin in real-world situations, contemplating the computational challenges and the authorized ambiguities surrounding copyright legal guidelines that have an effect on generative AI. It acknowledges that whereas the proposed mannequin goals to foster collaboration between AI builders and copyright house owners, the dynamic nature of copyright legal guidelines and the variety of information sources require a versatile and adaptable answer.

In conclusion, the analysis successfully addresses the urgent concern of copyright infringement in generative AI by proposing a complicated financial mannequin grounded in cooperative sport concept. Using the Shapley worth, the strategy quantitatively attributes honest compensation to copyright house owners based mostly on their contributions to the AI’s coaching information. Demonstrated by rigorous numerical experiments, the outcomes affirm the mannequin’s functionality to distribute royalties equitably, aligning the pursuits of AI builders and copyright holders. This strategy mitigates authorized dangers, and fosters continued innovation and collaboration within the burgeoning subject of AI-driven content material creation.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 40k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.

