
In AI, combining giant language fashions (LLMs) with tree-search strategies is pioneering the method of complicated reasoning and planning duties. These fashions, designed to simulate and enhance decision-making capabilities, are more and more vital in numerous purposes requiring a number of logical reasoning steps. Nevertheless, their efficacy is usually hampered by a big limitation: the lack to be taught from earlier errors and incessantly repeating errors throughout problem-solving.
A prevalent problem inside AI analysis is enhancing LLMs’ problem-solving accuracy with out manually reprogramming their underlying algorithms. This problem is particularly pronounced in duties that contain intensive planning and reasoning, equivalent to strategic game-playing or complicated problem-solving situations the place every determination impacts subsequent decisions. Present strategies, equivalent to breadth-first search (BFS) and Monte Carlo Tree Search (MCTS), whereas efficient in navigating these issues, don’t incorporate learnings from previous search experiences.
Researchers from the College of Info Science and Know-how, ShanghaiTech, and Shanghai Engineering Analysis Middle of Clever Imaginative and prescient and Imaging launched a novel framework known as Reflection on Search Bushes (RoT). This framework is particularly designed to reinforce the effectivity of tree-search strategies by permitting LLMs to mirror on and be taught from earlier searches. By integrating a sturdy LLM’s functionality to research previous tree search knowledge, RoT generates actionable pointers that assist forestall the repetition of previous errors. This revolutionary method leverages historic search experiences to bolster the decision-making processes of much less succesful LLMs.
The methodology behind RoT entails the delicate evaluation of prior search outcomes to formulate pointers for future searches. These pointers are meticulously crafted based mostly on key insights from analyzing actions and their penalties throughout previous searches. As an example, in complicated reasoning duties throughout numerous tree-search-based prompting strategies like BFS and MCTS, the introduction of RoT has considerably enhanced LLM efficiency. In sensible purposes, equivalent to strategic video games and problem-solving duties, RoT has demonstrated its functionality by bettering search accuracy and lowering repeated errors.
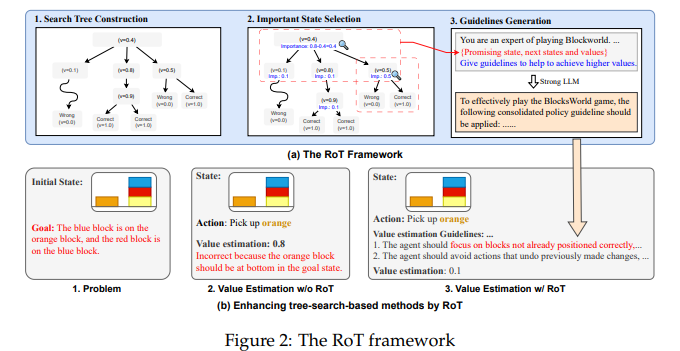
The effectiveness of the RoT framework is additional underscored by its substantial influence on efficiency metrics. For instance, in duties that employed BFS, the accuracy enhancements had been quantitatively vital. In tougher situations requiring the next variety of reasoning steps, RoT’s advantages had been much more pronounced, illustrating its scalability and flexibility to completely different ranges of complexity. Notably, RoT’s implementation led to a measurable discount within the repetition of errors, with experimental outcomes exhibiting a lower in redundant actions by as much as 30%, streamlining the search processes and enhancing total effectivity.
In conclusion, the Reflection on Search Bushes framework marks a transformative improvement in using giant language fashions for complicated reasoning and planning duties. By enabling fashions to mirror on and be taught from previous searches, RoT improves the accuracy and effectivity of tree-search-based strategies. It extends the sensible purposes of LLMs in AI. This development highlights the vital position of adaptive studying and historic evaluation within the evolution of AI applied sciences.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 40k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.


