
Speech synthesis has enormously progressed in technological developments, reflecting the human quest for machines that talk like us. As we stride into an period the place interactions with digital assistants and conversational brokers turn into commonplace, the demand for speech that echoes the naturalness and expressiveness of human communication has by no means been extra essential. The core of this problem lies in synthesizing speech that sounds human-like and aligns with people’ nuanced preferences in direction of speech, equivalent to tone, tempo, and emotional conveyance.
A staff of researchers at Fudan College has developed SpeechAlign, an progressive framework that targets the guts of speech synthesis, aligning generated speech with human preferences. In contrast to conventional fashions prioritizing technical accuracy, SpeechAlign introduces a fantastic shift by instantly incorporating human suggestions into speech technology. This suggestions loop ensures that the speech produced is technically sound and resonates on a human stage.
SpeechAlign distinguishes itself by means of its systematic strategy to studying from human suggestions. It meticulously constructs a dataset the place most popular speech patterns, or golden tokens, are positioned alongside much less most popular, artificial ones. This comparative dataset is the muse for a collection of optimization processes that iteratively refine the speech mannequin. Every iteration is a step in direction of a mannequin that higher understands and replicates human speech preferences, leveraging goal metrics and subjective human evaluations to gauge success.
A complete suite of evaluations from subjective assessments, the place human listeners rated the naturalness and high quality of speech to goal measurements like Phrase Error Charge (WER) and Speaker Similarity (SIM), SpeechAlign demonstrated its prowess. Fashions optimized with SpeechAlign achieved WER enhancements, with reductions as much as 0.8 in comparison with baseline fashions and enhancements in Speaker Similarity scores, touching the 0.90 mark. These metrics signify technical developments and point out a more in-depth mimicry of the human voice and its various nuances.
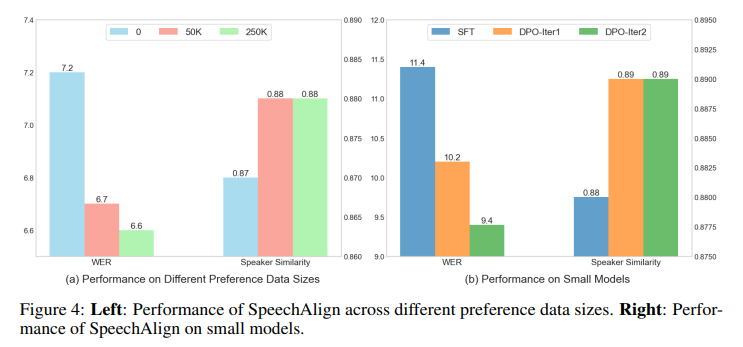
SpeechAlign showcased its versatility throughout totally different mannequin sizes and datasets. It proved that its methodology is powerful sufficient to boost smaller fashions and may generalize its enhancements to unseen audio system. This functionality is significant for deploying speech synthesis applied sciences in various eventualities, making certain that the advantages of SpeechAlign might be widespread and never confined to particular instances or datasets.
Analysis Snapshot

In conclusion, the SpeechAlign examine tackles the pivotal problem of aligning synthesized speech with human preferences, a niche that conventional fashions have struggled to bridge. The methodology innovatively incorporates human suggestions into an iterative self-improvement technique. It fine-tunes speech fashions with a nuanced understanding of human preferences and quantitatively improves upon essential metrics like WER and SIM. These outcomes underscore the effectiveness of SpeechAlign in enhancing the naturalness and expressiveness of synthesized speech.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to affix our 40k+ ML SubReddit
Whats up, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m presently pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m enthusiastic about know-how and need to create new merchandise that make a distinction.


