The appearance of enormous language fashions (LLMs) has ushered in a brand new period in computational linguistics, considerably extending the frontier past conventional pure language processing to embody a broad spectrum of normal duties. By their deep understanding and technology capabilities, these fashions can revolutionize varied industries by automating and enhancing duties beforehand regarded as solely throughout the human area. Regardless of these developments, a important problem stays: precisely evaluating these fashions in a fashion that displays real-world utilization and aligns with human preferences.
LLM analysis strategies usually depend on static benchmarks, using mounted datasets to measure efficiency in opposition to a predetermined floor reality. Whereas sensible for guaranteeing consistency and reproducibility, these strategies fail to seize real-world purposes’ dynamic nature. They should account for the nuanced and interactive elements of language use in on a regular basis eventualities, resulting in a niche between benchmark efficiency and sensible utility. This hole underscores the need for a extra adaptive and human-centric method to analysis.
The researchers from UC Berkeley, Stanford, and UCSD launched Chatbot Enviornment, a transformative platform that redefines the analysis of LLMs by putting human preferences at its core. Not like standard benchmarks, Chatbot Enviornment takes a dynamic method, inviting customers from numerous backgrounds to work together with completely different fashions by a structured interface. Customers pose a wide range of questions or prompts to which fashions reply. These responses are then in contrast side-by-side, with customers voting for the one which greatest aligns with their expectations. This course of ensures a broad spectrum of question varieties reflecting real-world use and locations human judgment on the coronary heart of mannequin analysis.
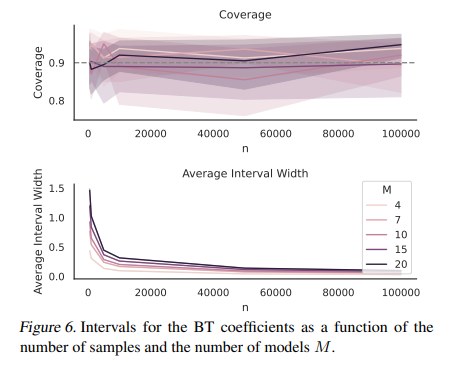
Chatbot Enviornment’s methodology stands out for its pairwise comparisons and crowdsourcing use to assemble in depth knowledge reflecting real-world purposes. Over a number of months, the platform has amassed greater than 240,000 votes, providing a wealthy dataset for evaluation. By making use of refined statistical strategies, the platform effectively and precisely ranks fashions primarily based on their efficiency, addressing the range of human queries and the nuanced preferences that characterize human evaluations. This method provides a extra related and dynamic evaluation of LLM capabilities and facilitates a deeper understanding of how completely different fashions carry out throughout varied duties.
Chatbot Enviornment’s in depth knowledge evaluation meticulously examines crowdsourced questions and consumer votes, and the analysis confirms the range and discriminative energy of the collected knowledge. This evaluation additionally reveals a major correlation between crowdsourced human evaluations and skilled judgments, establishing Chatbot Enviornment as a trusted and referenceable software within the LLM neighborhood. The platform’s widespread adoption and quotation by main LLM builders and corporations underscore its distinctive worth and contribution to the sector.
In conclusion, the contributions and findings introduced underscore the importance of Chatbot Enviornment as a pioneering platform for LLM analysis:
- Chatbot Enviornment introduces a novel, human-centric method to evaluating LLMs, bridging the hole between static benchmarks and real-world applicability.
- The platform captures numerous consumer queries by its dynamic and interactive methodology, guaranteeing a broad and real looking evaluation of mannequin efficiency.
- The in depth knowledge evaluation confirms the platform’s capability to supply a nuanced analysis of LLMs, highlighting the correlation between crowdsourced evaluations and skilled judgments.
- The success and credibility of Chatbot Enviornment are additional evidenced by its adoption and recognition throughout the LLM neighborhood, marking it as a key reference software for mannequin analysis.
Take a look at the Paper and Challenge. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Overlook to affix our Telegram Channel
You may additionally like our FREE AI Programs….
Good day, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at the moment pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m obsessed with expertise and wish to create new merchandise that make a distinction.