
Laptop imaginative and prescient researchers usually deal with coaching highly effective encoder networks for self-supervised studying (SSL) strategies. These encoders generate picture representations, however researchers often ignore the predictive a part of the mannequin after pretraining regardless of its potential to comprise helpful info. This analysis explores a special strategy, drawing inspiration from reinforcement studying: as an alternative of discarding the predictive mannequin, researchers examine if it may be reused for varied downstream imaginative and prescient duties.
This strategy introduces Picture World Fashions (IWM), extending the Joint-Embedding Predictive Structure (JEPA) framework (proven in Determine 2). Not like conventional masked picture modeling, IWM trains a predictor community to immediately apply photometric transformations (like coloration shifts, brightness modifications, and so on.) to picture representations inside latent house.
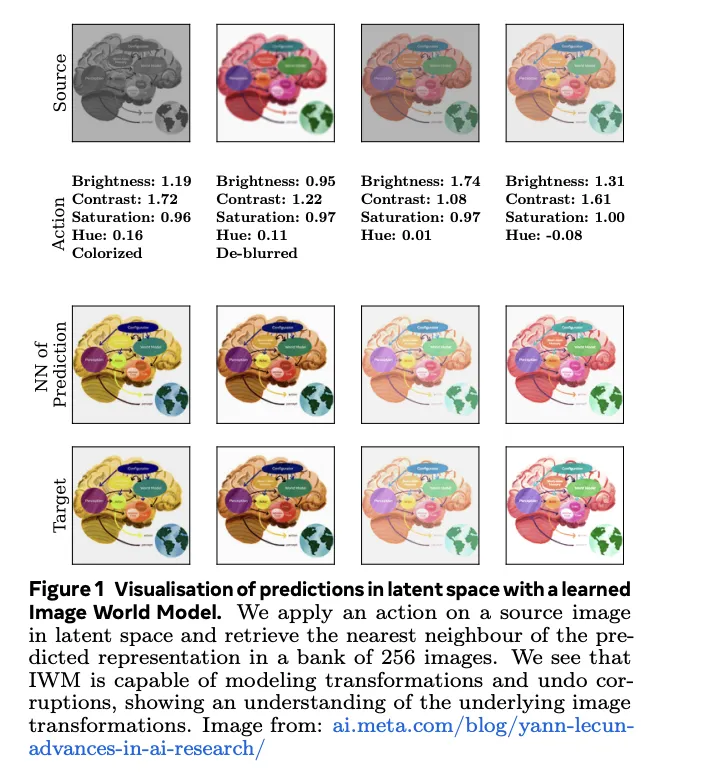
To coach an IWM, researchers begin with a picture and generate two distinct views. The primary view preserves most info by way of random cropping, flipping, and coloration jitters. The second view undergoes additional augmentations like grayscale, blur, and masking. Each views go by way of an encoder community to acquire latent representations. The crux of IWM lies in its predictor community, which makes an attempt to reconstruct the primary view’s illustration by making use of transformations in latent house (proven in Determine 1). Importantly, the predictor receives details about the particular transformations utilized, permitting it to tailor its actions.
Researchers found a number of key elements essential to constructing a succesful IWM predictor. How the predictor receives and processes details about the transformations, the energy of these transformations, and the predictor’s general capability (measurement and depth) all play important roles. A powerful IWM predictor learns equivariant representations, permitting it to grasp and apply picture modifications successfully. Conversely, weaker fashions are inclined to study invariant representations that concentrate on high-level picture semantics. This creates an intriguing tradeoff, permitting flexibility within the type of representations the mannequin learns.
Remarkably, finetuning the IWM predictor on downstream duties (picture classification, segmentation, and so on.) not solely yields important efficiency benefits over merely finetuning the encoder but additionally does so at a notably decrease computational price. This discovering hints at a doubtlessly extra environment friendly approach to adapt visible representations to new issues, which might have profound implications for the sensible utility of pc imaginative and prescient.
This exploration of Picture World Fashions means that the predictive part in self-supervised studying holds helpful and sometimes untapped potential and provides a promising path to higher efficiency in varied pc imaginative and prescient duties. The flexibleness in illustration studying and the numerous increase in effectivity and flexibility by way of predictor finetuning might revolutionize vision-based purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our Telegram Channel
You might also like our FREE AI Programs….
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s keen about analysis and the most recent developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.


