
Reinforcement Studying (RL) has turn out to be a cornerstone for enabling machines to deal with duties that vary from strategic gameplay to autonomous driving. Inside this broad subject, the problem of creating algorithms that be taught successfully and effectively from restricted interactions with their surroundings stays paramount. A persistent problem in RL is attaining excessive ranges of pattern effectivity, particularly when knowledge is proscribed. Pattern effectivity refers to an algorithm’s skill to be taught efficient behaviors from a minimal variety of interactions with the surroundings. That is essential in real-world functions the place knowledge assortment is time-consuming, pricey, or doubtlessly hazardous.
Present RL algorithms have made strides in enhancing pattern effectivity via progressive approaches similar to model-based studying, the place brokers construct inside fashions of their environments to foretell future outcomes. Regardless of these developments, constantly attaining superior efficiency throughout various duties and domains stays difficult.
Researchers from Tsinghua College, Shanghai Qi Zhi Institute, Shanghai and Shanghai Synthetic Intelligence Laboratory have launched EfficientZero V2 (EZ-V2), a framework that distinguishes itself by excelling in each discrete and steady management duties throughout a number of domains, a feat that has eluded earlier algorithms. Its design incorporates a Monte Carlo Tree Search (MCTS) and model-based planning, enabling it to carry out properly in environments with visible and low-dimensional inputs. This strategy permits the framework to grasp duties that require nuanced management and decision-making based mostly on visible cues, that are frequent in real-world functions.
EZ-V2 employs a mixture of a illustration operate, dynamic operate, coverage operate, and worth operate, all represented by subtle neural networks. These elements facilitate studying a predictive mannequin of the surroundings, enabling environment friendly motion planning and coverage enchancment. Notably noteworthy is the usage of Gumbel seek for tree search-based planning, tailor-made for discrete and steady motion areas. This technique ensures coverage enchancment whereas effectively balancing exploration and exploitation. Moreover, EZ-V2 introduces a novel search-based worth estimation (SVE) technique, using imagined trajectories for extra correct worth predictions, particularly in dealing with off-policy knowledge. This complete strategy permits EZ-V2 to attain exceptional efficiency benchmarks, considerably enhancing the pattern effectivity of RL algorithms.
From a efficiency standpoint, the analysis paper particulars spectacular outcomes. EZ-V2 reveals an development over the prevailing common algorithm, DreamerV3, attaining superior outcomes in 50 of 66 evaluated duties throughout various benchmarks, similar to Atari 100k. This marks a big milestone in RL’s capabilities to deal with complicated duties with restricted knowledge. Particularly, in features grouped underneath the Proprio Management and Imaginative and prescient Management benchmarks, the framework demonstrated its adaptability and effectivity, surpassing the scores of earlier state-of-the-art algorithms.
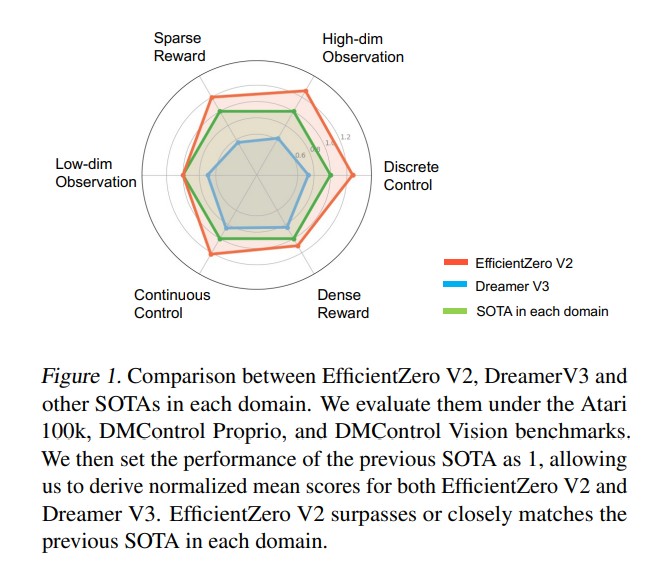
In conclusion, EZ-V2 presents a big leap ahead within the quest for extra sample-efficient RL algorithms. By adeptly navigating the challenges of sparse rewards and the complexities of steady management, they’ve opened up new avenues for making use of RL in real-world settings. The implications of this analysis are profound, providing the potential for breakthroughs in numerous fields the place knowledge effectivity and algorithmic flexibility are paramount.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to hitch our Telegram Channel
You may additionally like our FREE AI Programs….
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


