
Robotic manipulation has all the time introduced a big problem within the automation and AI fields, significantly with regards to duties that require a excessive diploma of dexterity. Conventional imitation studying strategies, which depend on human demonstrations to show robots advanced duties, have been restricted by the need for intensive, high-quality demonstration knowledge. Because of the intricacies concerned, this requirement usually interprets into appreciable human effort, particularly for multi-finger dexterous manipulation duties.
In opposition to this backdrop, this paper introduces a novel framework, CyberDemo (Determine 2), which makes use of simulated human demonstrations for real-world robotic manipulation duties. This strategy not solely mitigates the necessity for bodily {hardware}, thus permitting for distant and parallel knowledge assortment but additionally considerably enhances process efficiency by way of simulator-exclusive knowledge augmentation methods (proven in Determine 3). By leveraging these methods, CyberDemo can generate a dataset that’s orders of magnitude bigger than what may feasibly be collected in real-world settings. This functionality addresses one of many elementary challenges within the subject: the sim2real switch, the place insurance policies skilled in simulation are tailored for real-world software.
CyberDemo’s methodology begins with the gathering of human demonstrations by way of teleoperation in a simulated surroundings utilizing low-cost gadgets. This knowledge is then enriched by way of intensive augmentation to incorporate a wide selection of visible and bodily circumstances not current throughout the preliminary knowledge assortment. This course of is designed to enhance the robustness of the skilled coverage in opposition to variations in the actual world. The framework employs a curriculum studying technique for coverage coaching, beginning with the augmented dataset and steadily introducing real-world demonstrations to fine-tune the coverage. This strategy ensures a easy sim2real transition, addressing variations in lighting, object geometry, and preliminary pose with out necessitating extra demonstrations.
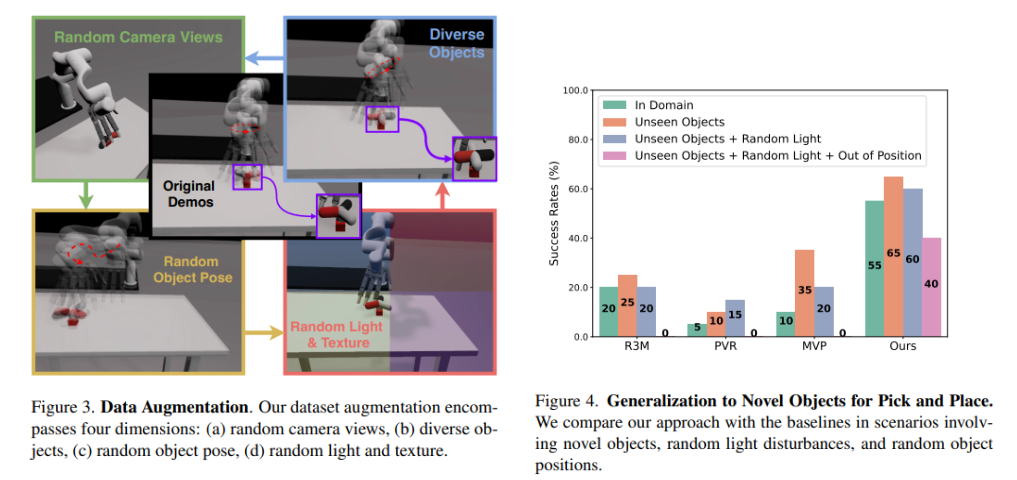
The effectiveness of CyberDemo is underscored by its efficiency (Determine 4) in varied manipulation duties. In comparison with conventional strategies, CyberDemo demonstrates a outstanding enchancment in process success charges. Particularly, CyberDemo achieves a hit price that’s 35% greater for quasi-static duties akin to choose and place and 20% greater for non-quasi-static duties like rotating a valve when put next in opposition to pre-trained insurance policies fine-tuned on real-world demonstrations. Moreover, in exams involving unseen objects, CyberDemo’s capability to generalize is especially noteworthy, with a hit price of 42.5% in rotating novel objects, a big leap from the efficiency of typical strategies.
This methodology is evaluated in opposition to a number of baselines, together with state-of-the-art imaginative and prescient pre-training fashions like PVR, MVP, and R3M, which have been beforehand employed for robotic manipulation duties. PVR builds on MoCo-v2 with a ResNet50 spine, MVP makes use of self-supervised studying from a Masked Autoencoder with a Imaginative and prescient Transformer spine, and R3M combines time-contrastive studying, video-language alignment, and L1 regularization with a ResNet50 spine. The success of CyberDemo in opposition to these well-established fashions highlights its effectivity and robustness and its capability to outperform fashions which were fine-tuned on real-world demonstration datasets.
In conclusion, CyberDemo’s revolutionary strategy, leveraging augmented simulation knowledge, challenges the prevailing perception that real-world demonstrations are paramount for fixing real-world issues. The empirical proof introduced by way of CyberDemo’s efficiency demonstrates the untapped potential of simulation knowledge, enhanced by way of knowledge augmentation, to surpass real-world knowledge when it comes to worth for robotic manipulation duties. Whereas the necessity to design simulated environments for every process presents a further layer of effort, lowering required human intervention for knowledge assortment and avoiding advanced reward design processes supply substantial benefits. CyberDemo represents a big step ahead within the subject of robotic manipulation, providing a scalable and environment friendly resolution to the perennial challenges of sim2real switch and coverage generalization.
Try the Paper and Venture. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
You may additionally like our FREE AI Programs….
Vineet Kumar is a consulting intern at MarktechPost. He’s presently pursuing his BS from the Indian Institute of Expertise(IIT), Kanpur. He’s a Machine Studying fanatic. He’s keen about analysis and the most recent developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.


