
Imaginative and prescient-language fashions in AI are designed to grasp and course of info from visible and textual inputs, simulating the human potential to understand and interpret the world round us. The intersection of imaginative and prescient and language understanding is essential for numerous purposes, from automated picture captioning to advanced scene understanding and interplay.
The problem at hand, nevertheless, is the event of fashions that may successfully combine and interpret visible and linguistic info, which stays a fancy downside. This problem is compounded by the necessity for fashions to grasp particular person components inside a picture or textual content and grasp the nuanced interaction between them.
Present strategies for image-text alignment in language fashions use caption knowledge. Nonetheless, the captions typically have to be longer and extra coarse-grained, resulting in noisy alerts and hindering alignment. The present scale of aligned knowledge is restricted, making it difficult to be taught long-tailed visible data. Increasing the amount of aligned knowledge from numerous sources is essential for a nuanced understanding of much less internationally famend visible ideas. Visible instruction datasets deal with easy questions and enhancing elementary talents relatively than advanced reasoning. The solutions in these datasets typically have to be longer, uninformative, and require sprucing or regeneration.
A crew of researchers from the Shenzhen Analysis Institute of Massive Information and the Chinese language College of Hong Kong presents a novel methodology for enhancing vision-language fashions. Their strategy, A Lite Language and Imaginative and prescient Assistant (ALLaVA) leverages artificial knowledge generated by GPT-4V to coach a lightweight model of huge vision-language fashions (LVLMs). This methodology goals to offer a extra resource-efficient resolution with out compromising on efficiency.
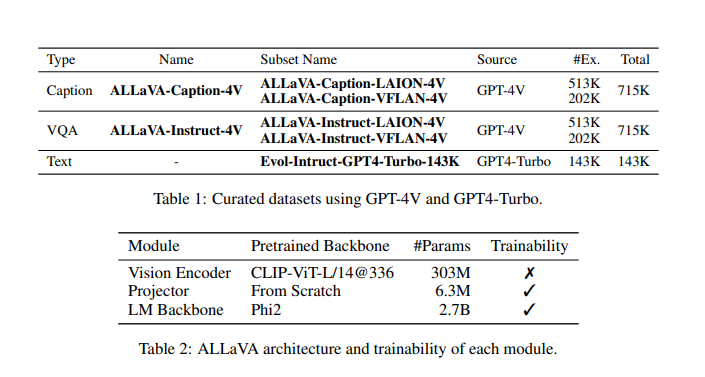
Leveraging GPT-4V, ALLaVA synthesizes knowledge by a captioning-then-QA methodology, specializing in pictures from Imaginative and prescient-FLAN and LAION sources. This course of includes detailed captioning, producing advanced questions for rigorous reasoning, and offering complete solutions. Moral tips are strictly adhered to, avoiding biased or inappropriate content material. The result consists of two expansive artificial datasets: ALLaVA-Caption and ALLaVA-Instruct, consisting of captions, visible questions and solutions (VQAs), and high-quality directions. The structure employs CLIP-ViT-L/14@336 for imaginative and prescient encoding and Phi2 2.7B for the language mannequin spine, making certain sturdy efficiency throughout numerous benchmarks.
The mannequin achieves aggressive efficiency on 12 benchmarks as much as 3B LVLMs. It will possibly obtain comparable efficiency with a lot bigger fashions, highlighting its effectivity and effectiveness. Ablation evaluation reveals that coaching the mannequin with ALLaVA-Caption-4V and ALLaVA-Instruct-4V datasets considerably improves efficiency on benchmarks. The Imaginative and prescient-FLAN questions are comparatively easy, specializing in enhancing elementary talents relatively than advanced reasoning. The success of ALLaVA underscores the potential of utilizing high-quality artificial knowledge to coach extra environment friendly and efficient vision-language fashions, making superior AI applied sciences extra accessible.

In conclusion, the mannequin developed within the analysis, ALLaVA, represents a big step ahead in growing gentle vision-language fashions. By using artificial knowledge generated by superior language fashions, the analysis crew has demonstrated the feasibility of making environment friendly but highly effective fashions able to understanding advanced multimodal inputs. This strategy addresses the problem of resource-intensive coaching and opens new avenues for making use of vision-language fashions in real-world situations.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our Telegram Channel
You might also like our FREE AI Programs….
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


