
Coaching Massive Language Fashions (LLMs) entails two foremost phases: pre-training on intensive datasets and fine-tuning for particular duties. Whereas pre-training requires important computational assets, fine-tuning provides comparatively much less new info to the mannequin, making it extra compressible. This pretrain-finetune paradigm has enormously superior machine studying, permitting LLMs to excel in numerous duties and adapt to particular person wants, promising a future with extremely specialised fashions tailor-made to particular necessities.
Numerous quantization methods, similar to rescaling activations, decomposing matrix multiplications, and iterative weight rounding, purpose to cut back reminiscence utilization and latency in LLMs. Moreover, pruning strategies induce sparsity by zeroing sure parameter values. Parameter-efficient fine-tuning (PEFT) approaches, like adapter layers and Low-Rank Adaptation (LoRA), cut back trainable parameters throughout fine-tuning, enhancing effectivity with out sacrificing accuracy. These strategies provide important potential for compression-aware coaching and multi-tenant serving programs.
Researchers from the Massachusetts Institute of Expertise, Princeton College, and Collectively AI have proposed BitDelta, which successfully quantizes fine-tuning deltas to 1 bit with out sacrificing efficiency. This discovery suggests potential redundancy in fine-tuning info and affords multi-tenant serving and storage implications. By using a high-precision base mannequin alongside a number of 1-bit deltas, BitDelta considerably reduces GPU reminiscence necessities by over 10×, thereby enhancing era latency in multi-tenant environments.
BitDelta employs a two-stage course of for environment friendly quantization of fine-tuning deltas in LLMs. Firstly, it quantizes every weight matrix delta right into a binary matrix multiplied by a scaling issue, initialized as the common absolute worth of the delta. Secondly, it calibrates scaling components through mannequin distillation over a small dataset, sustaining frozen binary matrices. BitDelta‘s effectivity permits for fast compression of fashions, facilitating shared server utilization and considerably decreasing GPU reminiscence consumption and inference latency.
BitDelta is evaluated in opposition to authentic uncompressed fashions and 8-bit RTN and 4-bit GPTQ quantization strategies. Throughout Llama-2 and Mistral mannequin households, BitDelta persistently performs nicely on high-margin metrics, usually outperforming baselines. It precisely preserves fine-tuned info, even surpassing GPTQ when utilized to quantized base fashions, showcasing its effectiveness and flexibility throughout completely different mannequin sizes and fine-tuning methods.
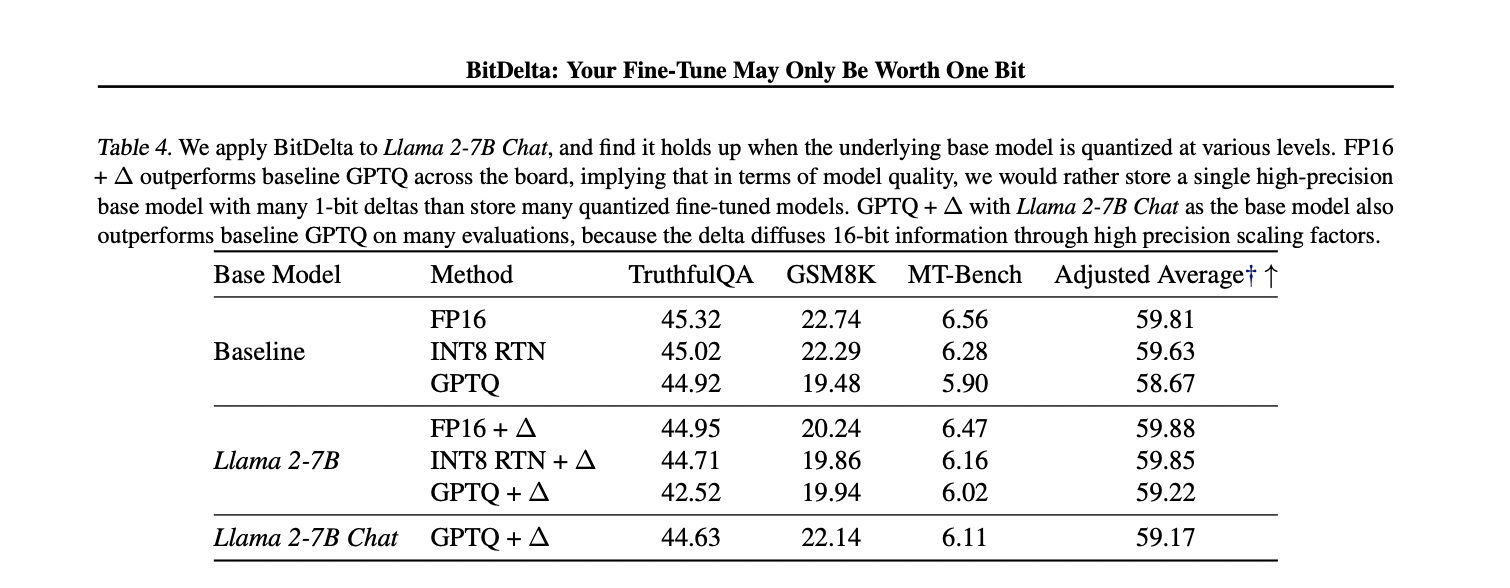
In conclusion, researchers from the Massachusetts Institute of Expertise, Princeton College, and Collectively AI have proposed BitDelta, a easy but highly effective methodology for quantizing weight deltas in LLMs right down to 1 bit, effectively representing a number of fine-tuned fashions with one base mannequin and a number of deltas. BitDelta achieves minimal efficiency degradation by means of distillation-based calibration whereas considerably decreasing GPU reminiscence necessities and enhancing era latency. This method paves the way in which for extra environment friendly mannequin deployment and useful resource utilization in machine studying functions.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our Telegram Channel
You might also like our FREE AI Programs….
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


