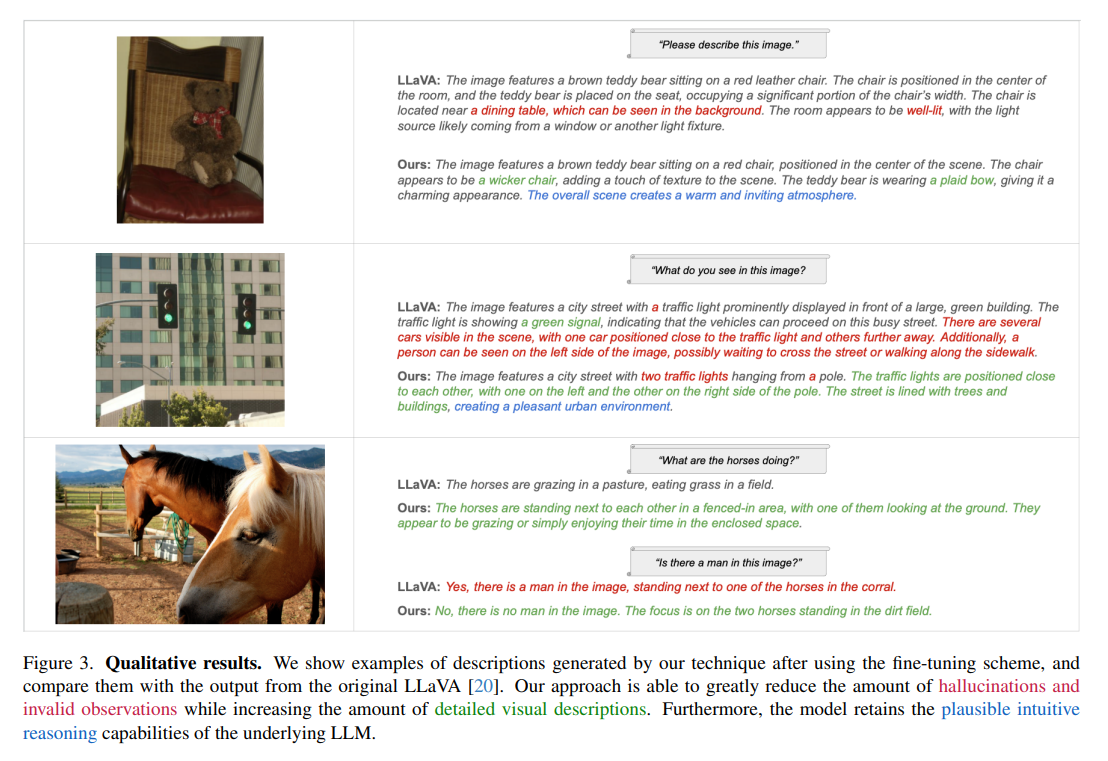
Integrating pure language understanding with picture notion has led to the event of huge imaginative and prescient language fashions (LVLMs), which showcase exceptional reasoning capabilities. Regardless of their progress, LVLMs typically encounter challenges in precisely anchoring generated textual content to visible inputs, manifesting as inaccuracies like hallucinations of non-existent scene parts or misinterpretations of object attributes and relationships.
Researchers from The College of Texas at Austin and AWS AI suggest the progressive framework ViGoR (Visible Grounding By way of Wonderful-Grained Reward Modeling) as an answer. ViGoR advances the visible grounding of LVLMs past conventional baselines via fine-grained reward modeling, participating each human evaluations and automatic strategies for enhancement. This method is notably environment friendly, clarifying the intensive prices of complete supervision sometimes required in such developments.
ViGoR’s methodology is especially notable for its strategic fine-tuning of pre-trained LVLMs, resembling LLaVA. By introducing a collection of photos accompanied by prompts to the LVLM, it generates a number of textual outputs for every. Human annotators then assess these image-text pairs, assigning detailed, sentence-level scores primarily based on the textual high quality. This course of cultivates a dataset encompassing image-text-evaluation triads. Subsequently, a reward mannequin skilled on this dataset refines the LVLM, considerably bolstering its visible grounding capabilities with a comparatively modest dataset of 16,000 samples.
ViGoR integrates an ingenious automated methodology to assemble the reward mannequin with out extra human labor, additional enhancing the visible grounding efficacy of LVLMs. The synergy between human-evaluated and automatic reward fashions underpins ViGoR’s complete answer, markedly enhancing LVLM efficiency in precisely grounding textual content in visible stimuli.
ViGoR’s efficacy is underscored by its superior efficiency over current baseline fashions throughout a number of benchmarks. A specifically curated, difficult dataset designed to check LVLMs’ visible grounding capabilities additional validated the framework’s success. To help continued analysis, the group plans to launch their human annotation dataset, comprising round 16,000 photos and generated textual content pairs with nuanced evaluations.
ViGoR stands out for a number of causes:
- It introduces a broadly relevant framework using fine-grained reward modeling to considerably improve the visible grounding of LVLMs.
- Creating reward fashions requiring minimal human effort showcases important enhancements in visible grounding effectivity.
- A complete and difficult dataset, MMViG, is constructed particularly to evaluate the visible grounding capabilities of LVLMs.
- A human analysis dataset that includes 16K photos and generated textual content pairs with detailed evaluations shall be launched, enriching assets for associated analysis endeavors.
In conclusion, ViGoR presents a big development in enhancing LVLMs’ visible grounding accuracy and retains the inherent artistic and intuitive reasoning capabilities of pre-trained fashions. This improvement heralds a extra dependable interpretation and era of textual content about photos, shifting nearer to fashions that perceive and describe visible content material with excessive constancy and element.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and Google Information. Be a part of our 37k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to affix our Telegram Channel
Howdy, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at present pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m captivated with know-how and wish to create new merchandise that make a distinction.