
Within the evolving panorama of Pure Language Processing (NLP), growing massive language fashions (LLMs) has been on the forefront, driving a broad spectrum of purposes from automated chatbots to stylish programming assistants. Nonetheless, the computational expense of coaching and deploying these fashions has posed important challenges. Because the calls for for greater efficiency and complexity develop, the necessity for revolutionary options to reinforce computational effectivity with out compromising on capabilities turns into paramount.
Enter the Combination-of-Consultants (MoE) idea, a promising strategy designed to scale mannequin parameters effectively by incorporating a number of specialised networks or specialists inside a bigger mannequin framework. The MoE structure permits dynamic enter routing to essentially the most related specialists, providing a pathway to attain superior process efficiency by a extra even handed use of computational sources.
A analysis initiative by researchers from the Nationwide College of Singapore, the College of Edinburgh, and ETH Zurich led to the creation of OpenMoE, a complete suite of decoder-only MoE-based LLMs starting from 650 million to a formidable 34 billion parameters. These fashions had been meticulously educated on an expansive dataset spanning over one trillion tokens, embodying numerous languages and coding information. The analysis staff’s dedication to openness and reproducibility has made OpenMoE’s full supply code and coaching datasets accessible to the general public, a transfer aimed toward demystifying MoE-based LLMs and catalyzing additional innovation within the discipline.
A cornerstone of OpenMoE’s improvement was its in-depth evaluation of MoE routing mechanisms. The analysis unearthed three pivotal findings: the prevalence of context-independent specialization, the institution of token-to-expert assignments early within the coaching section, and an inclination for later sequence tokens to be dropped. Such insights into the inside workings of MoE fashions are vital, revealing strengths and areas ripe for enchancment. For example, the noticed routing selections, largely primarily based on token IDs relatively than contextual relevance, pinpoint a possible avenue for optimizing efficiency, significantly in duties requiring sequential understanding, like multi-turn conversations.
OpenMoE’s efficiency analysis throughout numerous benchmarks demonstrated commendable cost-effectiveness, difficult the traditional knowledge that elevated mannequin measurement and complexity essentially entail proportional rises in computational demand. In direct comparisons, OpenMoE variants showcased aggressive, if not superior, efficiency towards densely parameterized fashions, highlighting the efficacy of the MoE strategy in leveraging parameter scalability for enhanced process efficiency.
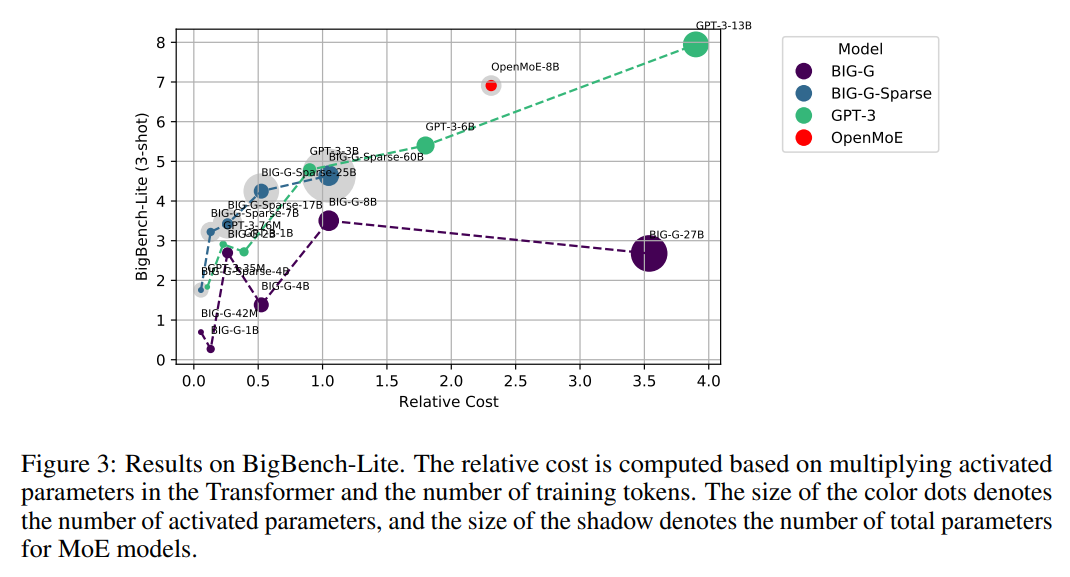
Past mere efficiency metrics, the OpenMoE challenge represents a major leap towards a extra accessible and democratic NLP analysis panorama. By sharing in-depth analyses, coaching methodologies, and the very fashions themselves, the analysis staff supplies a strong basis for future explorations into MoE-based LLMs. This open-source ethos not solely accelerates the tempo of innovation but additionally ensures that developments in NLP expertise stay inside attain of a broader neighborhood, fostering a extra inclusive discipline.

In conclusion, OpenMoE is a beacon of progress within the quest for extra environment friendly and highly effective language fashions. By its revolutionary use of MoE structure, complete evaluation of routing mechanisms, and exemplary dedication to openness, the challenge advances our understanding of MoE fashions. It units a brand new commonplace for future LLM improvement. Because the NLP neighborhood continues to grapple with the twin challenges of computational effectivity and mannequin scalability, OpenMoE presents each an answer and a supply of inspiration, paving the best way for the following technology of language fashions which might be each highly effective and pragmatically viable.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be a part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our Telegram Channel
Howdy, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m enthusiastic about expertise and wish to create new merchandise that make a distinction.


